Các kỹ thuật tối ưu hóa Data warehouse
- 9 minsTrong một bài viết trước, mình đã chia sẻ với các bạn những điểm giống và khác nhau giữa Database và Data warehouse bạn có thể xem lại tại đây. Cũng giống như tối ưu Database, việc tối ưu Data warehouse cũng là một công việc cực kỳ quan trọng, quyết định đến hiệu năng của toàn bộ hệ thống. Tuy nhiên do sự khác biệt về chức năng và thiết kế giữa 2 hệ thống này nên việc tối ưu hóa cho Data warehouse cũng có nhiều điểm khác biệt so với Database. Trong bài viết này, mình sẽ chia sẻ với các bạn một số kỹ thuật tối ưu hóa mà mình đang áp dụng cho sản phẩm Chainslake, hi vọng đây sẽ là các gợi ý tốt để có thể áp dụng cho hệ thống của các bạn.
Nội dung
- Tại sao cần tối ưu Data warehouse?
- Phương pháp tối ưu Data warehouse
- Phân vùng dữ liệu
- Xây dựng bảng trung gian
- Tối ưu câu truy vấn
- Kết luận
Tại sao cần tối ưu data warehouse?
Cũng giống như Database, một Data warehouse không được tối ưu sẽ dẫn đến việc các câu truy vấn chạy tốn nhiều thời gian, tốn nhiều chi phí tính toán thậm chí có thể không thực thi được. Nếu như ở Database chúng ta có thể thực hiện việc tối ưu bằng cách viết lại câu truy vấn tốt hơn, sử dụng thêm index, tuy nhiên với Data warehouse mọi chuyện không đơn giản như vậy vì một số nguyên nhân sau:
- Dữ liệu trong Data warehouse thường có kích thước lớn, số lượng bản ghi của bảng nhiều hơn trong database rất nhiều.
- Lượng dữ liệu thêm mới vào sẽ liên tục tăng lên theo thời gian, điều này do đặc điểm dữ liệu của Data warehouse là dữ liệu lịch sử, ghi lại sự thay đổi hoặc sự kiện, log… Trong khi đó ở Database, kích thước của bảng sẽ chỉ tăng lên đến một lượng nhất định sau đó sẽ duy trì ổn định hoặc tăng nhẹ, lúc này việc viết lại truy vấn và đánh index trên database sẽ đem lại hiệu quả.
- Database phục vụ cho hoạt động hàng ngày, vì vậy có thể dễ dàng tối ưu hóa hoặc đánh index để tối ưu cho một số query nhất định. Còn Data warehouse phục vụ phân tích dữ liệu nên số lượng câu truy vấn rất nhiều và đa dạng, mọi câu truy vấn đều cần được tối ưu, do đó việc đánh index để tối ưu là không khả thi.
Chính vì các lý do này mà việc tối ưu Data warehouse cần phải được quan tâm, xem xét cẩn thận ngay từ khâu thiết kế và tổ chức dữ liệu, chứ không phải đợi đến khi dữ liệu đã được đổ vào và phình ra rất lớn rồi mới tìm cách tối ưu thì khả năng cao là đã muộn ![]() .
.
Phương pháp tối ưu data warehouse
Phương pháp chung để tối ưu dành cho cả Database và Data warehouse là làm giảm số lượng bản ghi cần phải scan khi thực hiện câu truy vấn. Mình sẽ lấy một ví dụ như sau:
SELECT tx_hash FROM ethereum.transactions
WHERE block_date = date '2024-12-15';
Theo cách thông thường, để thực thi câu truy vấn này Database hoặc Data warehouse sẽ phải scan toàn bộ bảng ethereum.transactions (hiện đang chứa 2,6B bản ghi) để tìm tất cả các tx_hash trong ngày 15/12/2024, cách làm này đương nhiên là tốn thời gian và không hề tối ưu.
Đối với Database chúng ta có thể nghĩ đến việc đánh index lên column block_date của bảng ethereum.transactions, tuy nhiên với số lượng bản ghi tới 2.6B thì việc đánh index cũng sẽ mất rất nhiều thời gian. Thêm vào đó, với lượng dữ liệu được thêm vào liên tục, việc sử dụng index sẽ khiến việc thêm dữ liệu vào trở nên chậm hơn.
Trên Data warehouse có các kỹ thuật riêng để tối ưu, mình sẽ giới thiệu một số cách mà mình đang sử dụng cho sản phẩm Chainslake
Phân vùng dữ liệu
Phân vùng dữ liệu (Partition) là tổ chức dữ liệu trong 1 bảng thành nhiều file có kích thước hơp lý theo một hoặc một vài column.
Ví dụ: Nhận thấy rằng dữ liệu trong bảng transactions luôn được đổ vào theo thứ tự thời gian nên mình đã phân vùng bảng này theo block_date, dữ liệu trong 1 ngày cũng được chia thành nhiều file nhỏ hơn, mỗi file chứa dữ liệu trong 1 khoảng thời gian, được sắp xếp và không chồng lấn lên nhau. Việc này có thể thực hiện được bằng cách repartition trước khi ghi dữ liệu vào bảng:
val outputDf = ...
outputDf.repartitionByRange(col("block_date"), col("block_time"))
.write.format("delta")
.mode(SaveMode.Append)
.option("spark.sql.files.maxRecordsPerFile", 1000)
.partitionBy("block_date")
.saveAsTable("output_table")
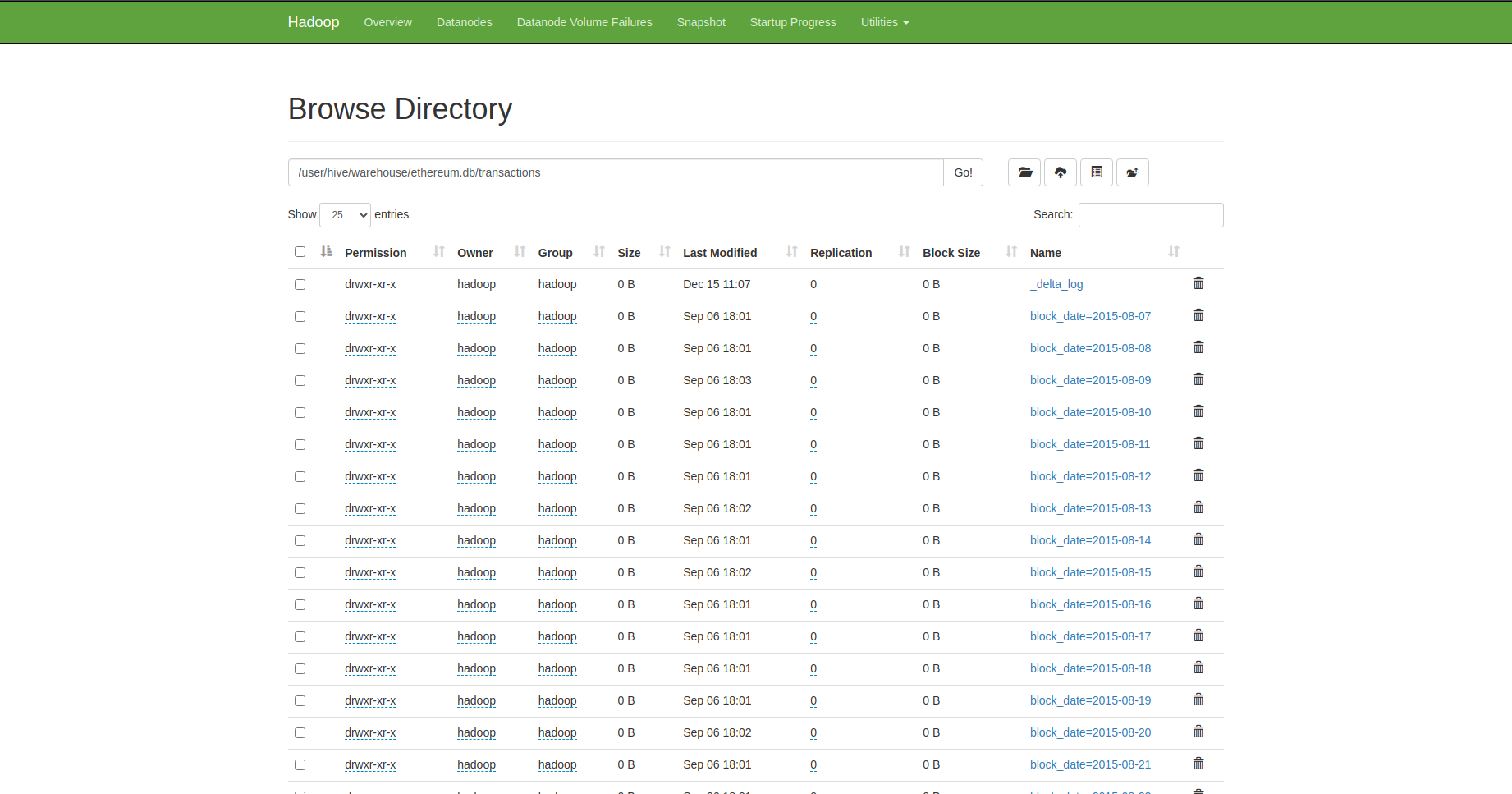
Do các bảng của mình sử dụng format Delta nên mỗi partition (tương ứng 1 file dữ liệu) sẽ được hệ thống file Delta quản lý và thu thập thông tin thống kê dữ liệu. Các thông tin này sau đó sẽ được sử dụng bởi query engine Trino, cho phép nó bỏ qua các file không chứa dữ liệu cần thiết khi thực thi truy vấn.
Ưu điểm: Đây là một phương pháp đơn giản, dễ thực hiện, không mất thêm chi phí lưu trữ dữ liệu nhưng có thể đem lại hiệu quả rất tốt, đặc biệt đối với các câu truy vấn cần filter hoặc join theo các column đã được partition.
Nhược điểm: Trong 1 bảng chỉ có thể thực hiện việc partition trên 1 hoặc 1 vài column có liên quan đến nhau ví dụ như block_date, block_time, block_number không thể thực hiện trên các column có nhiều khác biệt như block_date với tx_hash.
Kinh nghiệm: Mỗi partition nên có kích thước vừa phải, quá lớn hoặc quá nhỏ đều không tốt (có thể điều chỉnh bằng cấu hình spark.sql.files.maxRecordsPerFile).
Xây dựng bảng trung gian
Bảng dữ liệu trung gian là các bảng dữ liệu được kết hợp và tổng hợp từ các bảng dữ liệu raw ban đầu, chúng thường có kích thước nhỏ hơn rất nhiều, điều này giúp cho các truy vấn trên bảng trung gian trở nên đơn giản và nhanh hơn so với khi thực hiện trên các bảng dữ liệu raw.
Ví dụ: Để biết 1 ví trong 1 ngày bất kỳ đã chuyển và nhận những token nào, số lượng bao nhiêu, thay vì việc thực hiện truy vấn trên bảng ethereum_decoded.erc20_evt_transfer mình đã xây dựng bảng trung gian ethereum_balances.erc20_transfer_day tổng hợp sự thay đổi số dư mỗi ngày của tất cả các token của tất cả các ví. Từ đó việc truy vấn trên bảng ethereum_balances.erc20_transfer_day nhanh hơn rất nhiều so với bảng bảng transfer ban đầu. Đồng thời từ bảng transfer day mình cùng tổng hợp được bảng ethereum_balances.er20_native chứa số dư cuối cùng của tất cả ví một cách dễ dàng hơn.
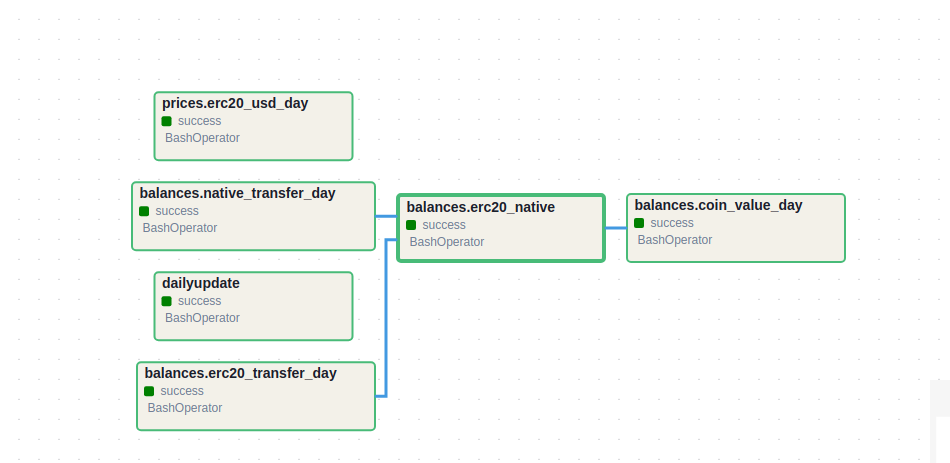
Ưu điểm: Nâng cao đáng kể hiệu quả truy vấn, đặc biệt khi kết hợp với partition. Giảm thiểu sự phức tạp khi viết truy vấn, giúp truy vấn dễ đọc và dễ hiểu hơn.
Nhược điểm: Tốn thêm không gian để lưu trữ bảng trung gian, tốn chi phí tính toán để duy trì update dữ liệu cho bảng trung gian.
Kinh nghiệm: Nên cân nhắc trước khi xây một bảng trung gian mới, chỉ nên làm nếu thực sự cần thiết và đem lại hiệu quả giúp tối ưu cho nhiều truy vấn quan trọng.
Tối ưu câu truy vấn
Việc phân vùng hay xây dựng bảng trung gian sẽ chẳng có ý nghĩa gì nếu câu truy vấn không được viết để sử dụng chúng. Vì vậy sau đây là một số lưu ý của mình khi viết truy vấn:
- Luôn sử dụng filter hoặc join các bảng bằng column được partition bất cứ khi nào có thể, càng sớm càng tốt vì việc lọc bớt các dữ liệu không cần thiết từ sớm sẽ giúp cải thiện hiệu năng truy vấn rất nhiều.
Ví dụ: Nếu cần join 2 bảngethereum.transactionsvàethereum.logstheo columntx_hashtrong ngày 15/12/2024, hãy thực hiện việc lọc dữ liệu trên cả 2 bảng trong ngày 15/12/2024 trước rồi sau đó mới join theotx_hash. - Ưu tiên sử dụng các bảng trung gian đang có sẵn trước khi nghĩ đến việc truy vấn trên các bảng dữ liệu raw.
Ví dụ: thay vì việc tính số dư của một ví bằng cách lọc và tổng hợp từ bảngethereum_decoded.erc20_evt_transfer, hãy sử dụng bảngethereum_balances.erc20_native, ngay cả khi bảng balances chỉ cho biết số dư của ví cho đến hết ngày hôm qua thì việc sử dụng kết quả này kết hợp cùng dữ liệu transfer được lọc chỉ trong ngày hôm nay cũng sẽ chạy nhanh hơn rất nhiều.
Kết luận
Trong bài viết này, mình đã giới thiệu với các bạn một số kỹ thuật tối ưu hóa Data warehouse mà mình đã sử dụng khi xây dựng Chainslake, hi vọng có thể giúp ích cho các bạn. Hẹn gặp lại các bạn trong các bài viết sau!