Cấu hình HDFS với độ sẵn sàng cao (High Availability)
- 8 minsThông qua các thử nghiệm trong bài viết giới thiệu về HDFS (bạn có thể xem lại tại đây), chúng ta đã thấy được rằng, hệ thống vẫn có thể hoạt động bình thường, dữ liệu không bị ảnh hưởng ngay cả khi có một số Datanode gặp lỗi. Tuy nhiên hệ thống này vẫn chưa đạt được tính sẵn sàng cao do vẫn còn 1 điểm yếu tại Namenode, khi Namenode gặp lỗi, toàn bộ cụm HDFS sẽ không thể hoạt động được. Trong bài viết này, mình sẽ hướng dẫn cách cấu hình cụm Hadoop với nhiều Namenode để đạt được tính sẵn sàng cao (High Availability).
Nội dung
Giới thiệu tổng quan
Trước hết mình sẽ nhắc lại một chút về vai trò của Namenode trong hệ thống HDFS, nó là node quản lý, nơi lưu trữ thông tin Metadata như tên file, cây thư mục, quyền truy cập, vị trí của các block trong Datanode. Nhờ có Namenode mà việc đọc ghi dữ liệu trên HDFS trở nên đơn giản như trên hệ thống file thông thường, Namenode giống như một tấm bản đồ trong hệ thống HDFS. Bất kỳ thao tác đọc ghi dữ liệu nào trên HDFS đều phải đi qua Namenode, điều này khiến cho nó trở thành điểm yếu huyệt trong toàn hệ thống.
Để giải quyết vấn đề này, hệ thống HDFS cần có nhiều Namenode hơn, tuy nhiên điều này không có nghĩa là tất cả các Namenode có thể cùng nhau hoạt động. Trong môi trường đa ứng dụng, đa luồng và phân tán, việc có nhiều Namenode cùng hoạt động chắc chắn sẽ dẫn xung đột nếu không có cơ chế đồng thuận. Trong thực tế, kiến trúc HDFS với HA chỉ cho phép 1 Namenode hoạt động (active) tại 1 thời điểm, nó sẽ tiếp nhận các yêu cầu đọc ghi dữ liệu và cập nhật Metadata. Các Namenode khác ở hoạt động ở chế độ chờ (Standby) chúng sẽ liên tục đồng bộ dữ liệu từ Active Namenode để đảm bảo dữ liệu Metadata của chúng luôn được cập nhật mới nhất từ Active NameNode.
Khi Active Namenode bị lỗi, 1 Standby Namenode khác sẽ được kích hoạt để trở thành Active Namenode mới. Việc lựa chọn Standby Namenode sử dụng thuật toán bầu lãnh đạo (Leader Election), sau đây là kiến trúc của hệ thống HDFS với High Availability.
Kiến trúc hệ thống
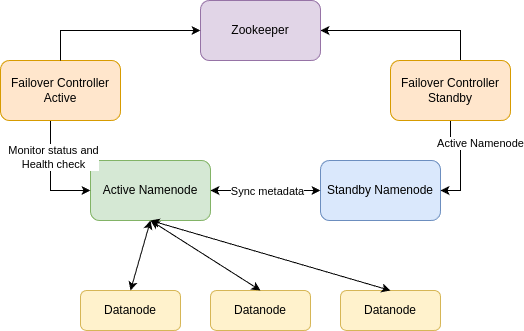
- Active Namenode: Namenode đang được kích hoạt ở trạng thái hoạt động, đóng vai trò là Namenode chính để quản lý và lưu trữ thông tin Metadata cho hệ thống HDFS.
- Standby Namenode: Các Namenode ở chế độ chờ, chúng sẽ đồng bộ dữ liệu Metadata từ Active Namenode
- Failover Controller: Trình quản lý Namenode được chạy trên mỗi node có Namenode, có nhiệm vụ theo dõi trạng thái hoạt động của Active Namenode và kích hoạt Standby Namenode khi cần thiết.
- Zookeeper Service: Lựa chọn Standby Namenode nào sẽ được kích hoạt, mình sẽ trình bày kỹ hơn về Zookeeper trong các bài viết sau nhé.
Cài đặt và cấu hình
Mình sẽ kích hoạt HA cho cụm Hadoop đang có (bạn có thể xem lại cách cài đặt tại đây). Cụm hadoop hiện tại đã có Namenode trên node01, mình sẽ cấu hình để có thêm 1 Namnode nữa trên node02.
Đầu tiên chúng ta sẽ cài Zookeeper, bạn có thể tìm thấy phiên bản mới nhất của Zookeeper tại đây
$ wget https://dlcdn.apache.org/zookeeper/zookeeper-3.9.1/apache-zookeeper-3.9.1-bin.tar.gz
$ tar -xzvf apache-zookeeper-3.9.1-bin.tar.gz
$ mv apache-zookeeper-3.9.1-bin /lib/zookeeper
$ chgrp hadoop -R /lib/zookeeper
$ chmod g+w -R /lib/zookeeper
Lưu ý: Để cho đơn giản thì mình sẽ cài Zookeeper trên 1 node (node01), trong thực tế để đảm bảo HA chúng ta nên cài Zookeeper trên 3 node
Tạo user Zookeeper
$ useradd -g hadoop -m -s /bin/bash zookeeper
Cấu hình Zookeeper trong file /lib/zookeeper/conf/zoo.cfg:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/home/zookeeper/data
clientPort=2181
Chạy Zookeeper service:
[zookeeper]$ /lib/zookeeper/bin/zkServer.sh start
Tiếp theo mình sẽ cấu hình để node02 trở thành Namenode, cần lưu ý rằng việc cấu hình phải thực hiện trên tất cả các node của cụm Hadoop. Trước khi bắt đầu mình sẽ shutdown cụm Hadoop:
Trên node01
$ $HADOOP_HOME/sbin/stop-all.sh
Bổ sung cấu hình cho file $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
...
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>file:///home/hdfs/ha-name-dir-shared</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence(hdfs:22)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_rsa</value>
</property>
</configuration>
Chỉnh sửa cấu hình trong file $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
...
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
</configuration>
Tạo thư mục share trong thư mục home của user hdfs:
[hdfs]$ mkdir ~/ha-name-dir-shared
Lưu ý: Private key của user hdfs phải được generate bằng thuật toán RSA, bạn có thể thực hiện bằng lệnh sau:
[hdfs]$ ssh-keygen -m PEM -P '' -f ~/.ssh/id_rsa
Sau khi đã thực hiện việc cấu hình trên tất cả các node, tiếp theo mình sẽ tiến hành đồng bộ dữ liệu name (Metadata) từ node01 sang node02
Bật Namenode trên node01
hdfs@node01:~$ $HADOOP_HOME/bin/hdfs --daemon start namenode
Khởi tạo dữ liệu name cho node02
hdfs@node02:~$ hdfs namenode -bootstrapStandby
Trở lại node1 để khởi tạo dữ liệu trong Zookeeper, sau đó tắt Namenode trên node01
hdfs@node01:~$ hdfs zkfc -formatZK
hdfs@node01:~$ $HADOOP_HOME/bin/hdfs --daemon stop namenode
Đến đây việc cài đặt và cấu hình đã xong, giờ chúng ta sẽ thử nghiệm xem sao nhé
Thử nghiệm
Bật lại tất cả các service của Hadodop
hdfs@node01:~$ $HADOOP_HOME/sbin/start-all.sh
Kiểm tra trên giao diện Namenode của node01 và node02:
-
http://node01:9870/dfshealth.html#tab-overview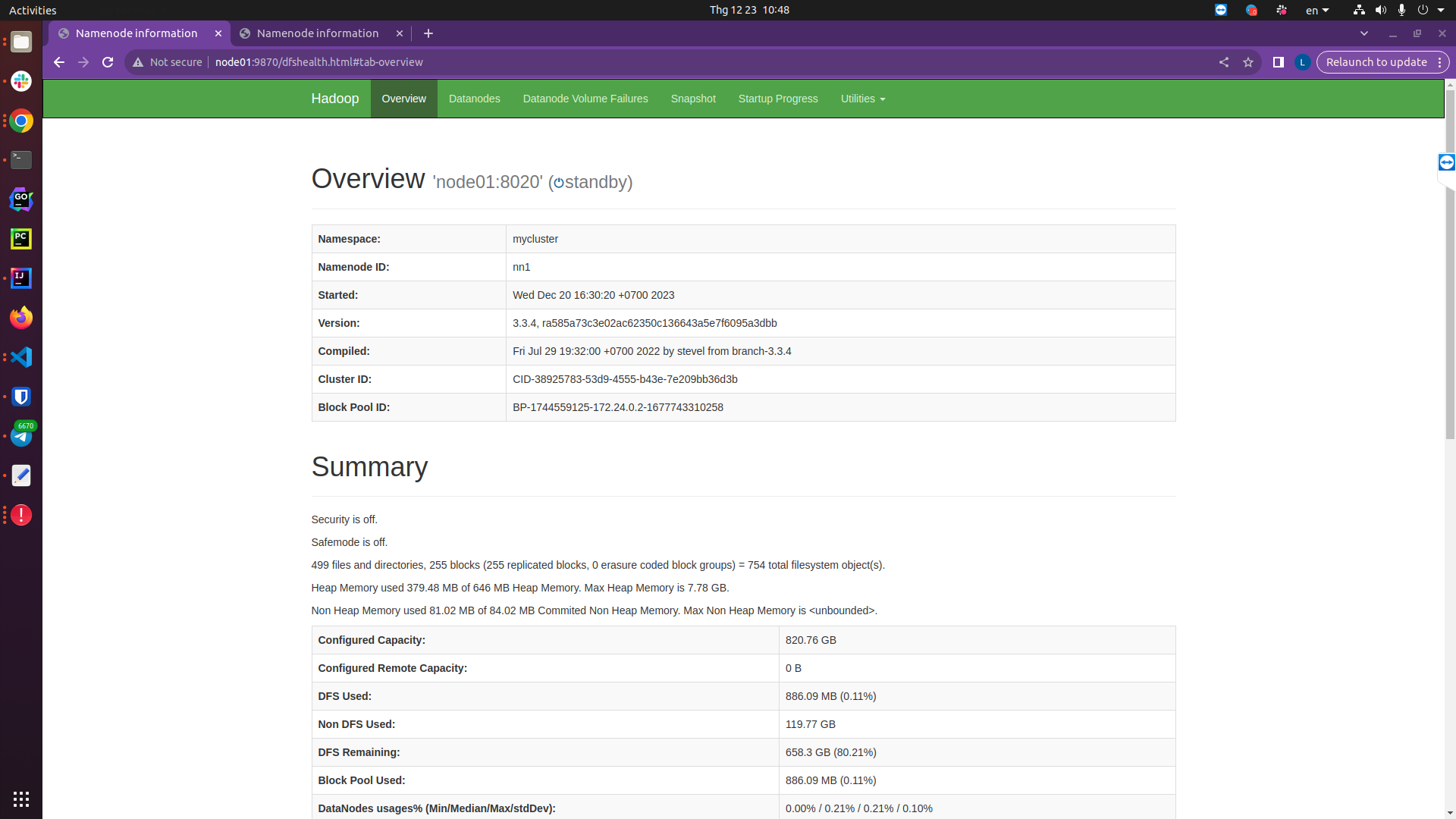
-
http://node02:9870/dfshealth.html#tab-overview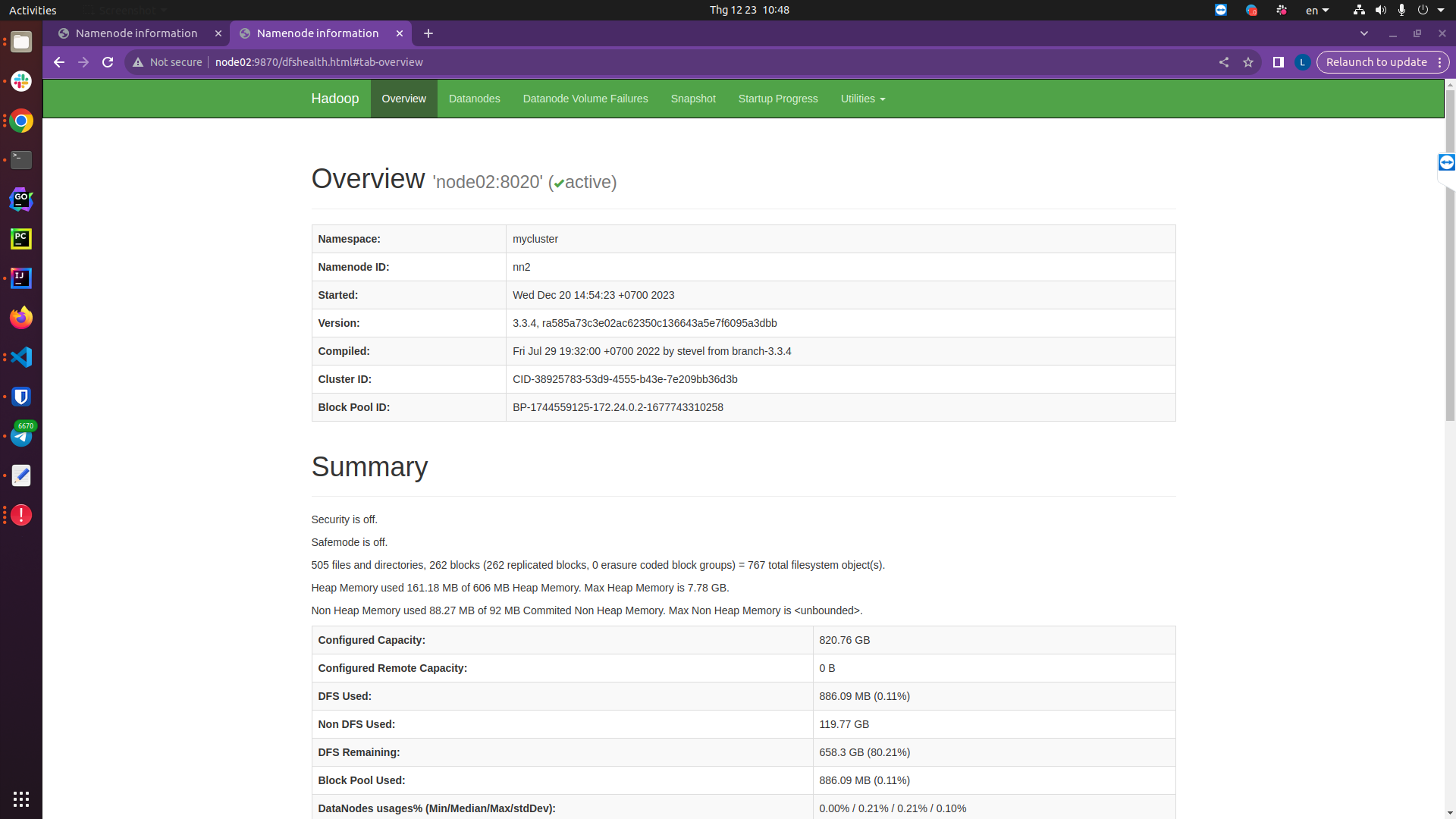
Bạn có thể thấy rằng Namenode 02 đang được active, còn Namenode 01 đang standby, giờ mình sẽ tắt namenode 02 để xem chuyện gì sẽ xảy ra
Trên node02:
hdfs@node02:~$ $HADOOP_HOME/bin/hdfs --daemon stop namenode
Lúc này namenode01 được kích hoạt để chuyển trạng thái thành active:
http://node01:9870/dfshealth.html#tab-overview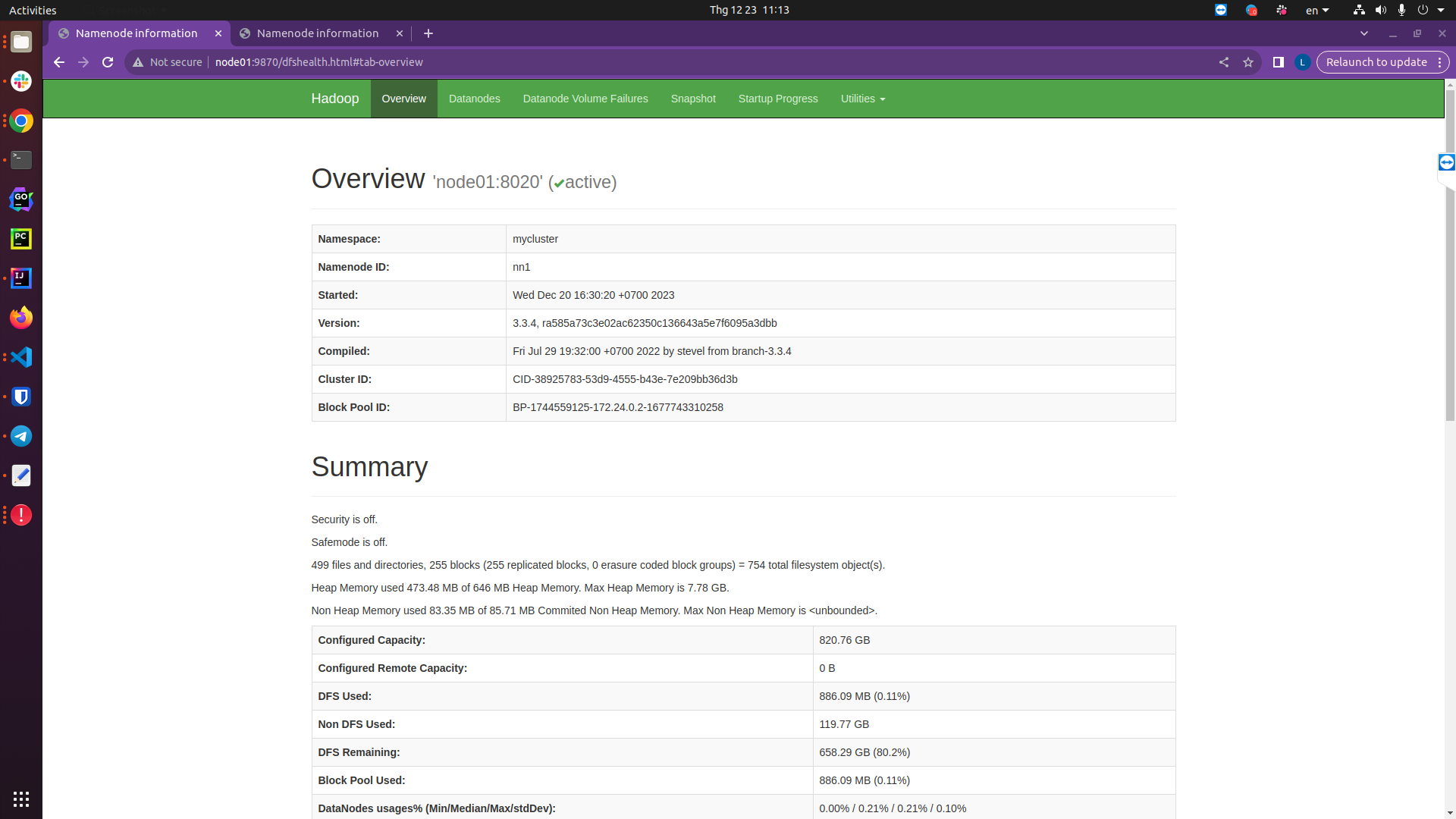
Để kiểm tra và chuyển trạng thái của các namenode bằng tay chúng ta có thể sử dụng tiện ích haadmin:
hdfs@node01:~$ hdfs haadmin [-ns <nameserviceId>]
[-transitionToActive <serviceId>]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-getAllServiceState]
[-checkHealth <serviceId>]
[-help <command>]
Lưu ý: Khi kích hoạt HA trên HDFS, chúng ta sẽ cần cấu hình lại các ứng dụng có sử dụng HDFS:
Cấu hình lại file $SPARK_HOME/conf/hive-site.xml và $HIVE_HOME/conf/hive-site.xml:
<configuration>
...
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://mycluster/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
...
</configuration>
Thay đổi location của schema và table trong datawarehouse
root@node01:~$ hive --service metatool -updateLocation hdfs://mycluster hdfs://node1:9000
Cấu hình hive catalog trong Trino $TRINO_HOME/etc/catalog/hive.properties:
hive.config.resources=/lib/hadoop/etc/hadoop/core-site.xml,/lib/hadoop/etc/hadoop/hdfs-site.xml
Kết luận
Trong bài viết này mình đã trình với các bạn cách Enable HA trên hệ thống HDFS, việc này sẽ giúp cho hệ thống HDFS hoạt động với khả năng sẵn sàng cao, từ đó năng cao tính ổn định cho toàn hệ thống. Hẹn gặp lại các bạn trong các bài viết tiếp theo.