Deploy Blockchain Data Warehouse like Dune Analyst on AWS from 2000$ per month
- 9 minsBefore we get started, you need to note that this is just my suggestion based on the minimum needs for the system to work, it takes more things and of course more money to make it work on production, however it would be a good starting point.
Content
Questions & Answers
Why “like Dune Analyst”?
-
If you don’t know Dune Analyst you can read about it in here, this is a great product if you are locking for a tool similar to Google but on Web3. There are so many analyst dashboards on blockchain protocols built by community on Dune. If you know SQL, you can write data queries on Dune’s available tables to build your own dashboards. Please learn carefully about Dune and how to use it before continuing to read this article.
-
The reason I wanted to build a data warehouse like Dune is because Dune is an open data warehouse, which allows everyone to see how they have built the tables in the data warehouse, you can see in Spellbook project of Dune on Github. I can take advantage of what Dune has already built instead of doing everything from scratch.
Why do I want to have my own data warehouse instead of using it directly on Dune?
-
First of all, I can do everything with my data warehouse without any limit, I can add functions that I need but don’t have on Dune, my applications can easily Accessing data in the warehouse, I can use the data for many different purposes such as building AI models, providing it to third parties… I can optimize to handle my own problems efficiently.
-
I can work with any blockchain EVM without being dependent on support from Dune. For example, new small chains do not yet have data on Dune.
-
I can join blockchain data with my private data without worrying about security issues on Dune.
System architecture
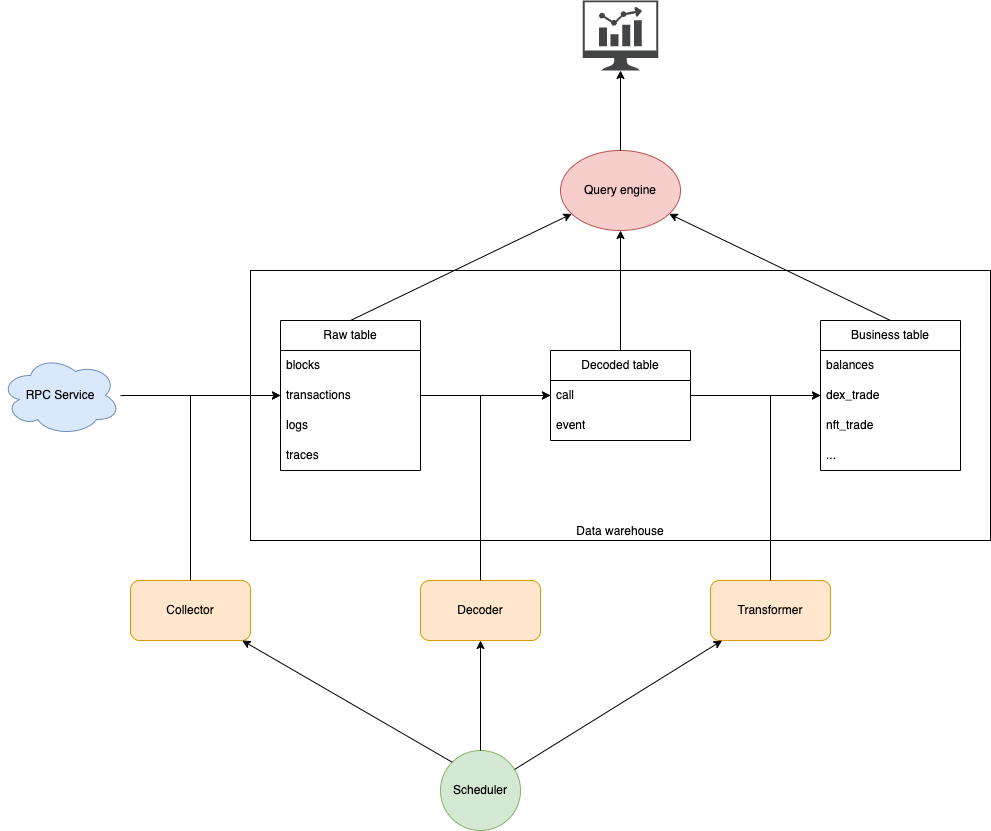
The figure above describes the system’s component architecture and data flow. Now I’m going to show you the details of this system
Data warehouse
This is the infrastructure that stores all of the system’s data, You can learn more about data warehouse in my article here.
From a technical perspective, there are two points to note:
- To deploy on AWS, I use Glue-S3, in which S3 will store data and Glue will store metadata information of tables in the warehouse. This allows me to store large amounts of data at low cost, plus Glue-S3 is also compatible with many query engines such as Trino, Athena, Pestro…
- The table format I use in the warehouse is Delta, you can read more about this format here. The reason for this choice is because Dune also uses it, I wanted the system to be as similar to Dune as possible to ensure compatibility and maximum utilization.
About data table, the tables in our data warehouse are divided into 3 groups:
- Raw tables: The data in these tables is taken directly from the API provided by the RPC service, For each EVM chain we have 4 raw data tables:
- Block: Table stores information about blocks of a chain
- Transactions: Table stores information about transactions
- Traces: Table stores information about internal transactions. When a transaction is performed, one contract can call a function of another contract and possibly more. Each time, an internal transaction will be created
- Logs: Table stores information about logs data. When a transaction is executed, it may emit Logs data to serve tracking depending on the logic code of the contract. You can read more about these tables in the Dune documentation
- Decoded tables: When decoding raw data of protocols, we will get decoded data. Note that in our raw data tables we already have all the raw data of each chain, so for each protocol we only need to use that protocol’s ABI to decode the raw data. There are 2 types of decoded tables:
- Call: The data in this table is decoded from the Traces table along with the corresponding ABI of the protocols. Each table will contain call data of one Call of many different contracts (if they use the same ABI for that Call).
- Event: The data in this table is decoded from the Logs table along with the corresponding ABI of the protocols. Each table will contain event data of one Event of many different contracts (if they use the same ABI for that Event).
- Bussiness tables: Tables to serve specific use cases are joined and aggregated from raw and decoded tables, on Dune they are known in the Spellbook project
RPC Service
RPC service is not part of our system, it acts as the raw data provider of each blockchain, you can learn more about RPC API here. Now I’ll tell you which RPC API each of our raw tables comes from.
- Blocks: Will be retrieved from the api eth_getblockbynumber, You should use the option to get all transactions of the block.
- Transactions: Will be retrived from the api eth_gettransactionreceipt. The input of this api is the tx_hash of the transaction, you can get it in the transactions list of each block. You can use data from the eth_getblockbynumber API for the transactions table, however I do not recommend it, you can read about the difference between transactions and transactions receipt here
- Logs: Will be retrieved from the api eth_getlogs
- Traces: Will be retrived from the api debug_traceTransaction
Note: The data in the raw tables in some cases may not represent what actually happened on the blockchain (when the transaction execution failed, then both logs and traces in that transaction will not be recognized). To know whether a transaction has been executed successfully or not, we need to rely on the status of the transaction in the transaction receipt.
Other components and technical stack
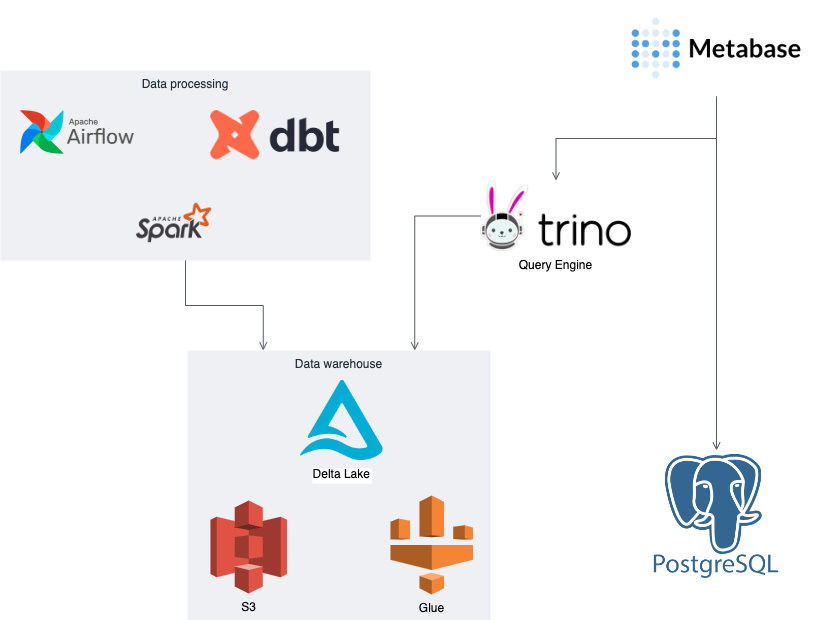
- Collector: The task is to call the RPC API to get raw data from RPC.
- Decoder: The task is to decode raw data into call or event data, using ABI provided from protocols
Both collector and decoder are Spark jobs, this allows me to configure data processing of multiple blocks concurrently, thereby increasing data processing capacity.
- Transformer: The task is to transform raw data and decode data into business data serving specific use cases. The task is to transform raw data and decode data into business data serving specific use cases. The Transformer base on DBT is similar to Dune’s Spellbook project, which allows me to reuse the existing source code on Spellbook.
- Scheduler: Task manager and coordinator for the entire system, I use Airflow to do this.
- Query engine: Allows clients to query data in the data warehouse using SQL language. I chose Trino because Dune is also using this query engine.
- BI Tool: To query and visualize data into dashboards I use the self-hosted open source version of Metabase
Deployment infrastructure
Below is a diagram of Three-tier infrastructure deployment on AWS for this system. You can read more about the Three-tier architecture in here.
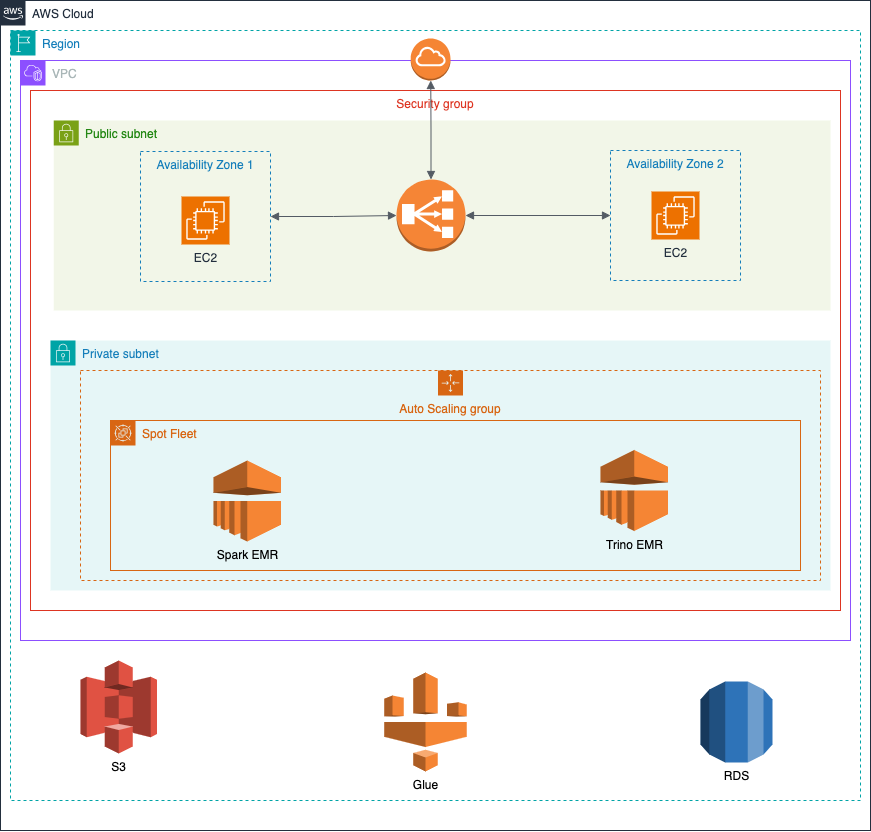
- Presentation tier: Deploy the BI Metabase tool, where users can write queries and build dashboards. It is deployed in the public subnet of VPC, on two Zones with Load balancer to ensure service availability
- Logic tier: Where data is calculated and queried. There are 2 EMR clusters, one is used for calculation and data processing, the other is used for query engine, this makes it easy to maintain and expand depending on usage needs. Both EMR clusters are deployed on EC2 with part of the computation performed on Spot instances to save costs, along with auto scaling capabilities that allow the system to automatically expand according to usage needs.
- Data tier: Where all system data is stored, including data in the data warehouse (Glue-S3) and application data in the database (RDS).
Cost calculation
The cost will depend on usage needs, I will take a specific case of building a datawarehouse for Ethereum blockchain for this estimate.
Ethereum information:
- Block height: 19.651.256
- Total transactions: 2.333,51 Millions
- Number transactions per date (avg): 1.207.914
According to my practical experience, for every 1 million transactions we will need about 4 GB of storage and processing capacity. So with ethereum we will need to process and store 9.3 TB of data and every day after that we need to process and store another 5 GB of data. I will base on this data to determine the size of our warehouse system.
First, of course, we need 9.3 TB of storage on S3 for all Ethereum data. Regarding computing ability, I will divide it into 2 categories as follows:
- Computational resources for data processing
- Compute resources for data querying
All calculations will be deployed on 2 EMR clusters as I presented in the infrastructure architecture section. For each EMR cluster, we need at least 3 EC2 nodes, of which there will be 1 primary node responsible for managing the entire cluster and not responsible for calculation. Since the data we have stored on S3 instead of EMR’s HDFS, we will only need 1 core node. Computation and data processing work will be performed on core nodes and task nodes. You can see more about EMR estimate capacity here. To ensure system stability and save costs, I recommend using on-demand EC2 for Primary and Core nodes, and Sport instances for Task nodes. I’m using the benchmark results here to estimate that 1 CPU on EMR can process 26 GB of data in 1 hour.
To calculate infrastructure costs, I use the AWS Calculator tool. My estimated total cost is about 1800$~2000$ per month, you can see the details here. With this configuration we can collect, process and store all historical data of Ethereum in about 7 days (according to theoretical calculations).
Conclusion
In this article, I have proposed a proposal to deploy a data warehouse infrastructure for the Ethereum blockchain. Thank you for reading, see you in the next articles.