HDFS - Hệ thống File phân tán
- 9 minsHDFS (Hadoop Distributed File System) được coi là nền tảng của cả hệ sinh thái Hadoop. Không chỉ là một nơi lưu trữ dữ liệu, HDFS còn có rất nhiều công nghệ quan trọng được sử dụng trong phát triển các ứng dụng phân tán. Trong bài viết này mình sẽ giải thích về HDFS thông qua những thử nghiệm trực tiếp với nó, hi vọng sẽ giúp các bạn dễ dàng hình dung hơn.
Nội dung
Giới thiệu tổng quan
HDFS dựa trên ý tưởng từ bài báo Google File System xuất bản tháng 10 năm 2003, trong đó trình bày những mô tả sơ lược về Distributed File System với các đặc điểm sau:
- Tính phân tán: Dữ liệu được chia nhỏ thành các block và lưu trữ trên nhiều máy tính, tuy nhiên vẫn cung cấp một giao diện cho phép người dùng và các ứng dụng làm việc như với hệ thống file thông thường.
- Khả năng mở rộng: Có thể tăng dung lượng lưu trữ bằng cách bổ sung các node (máy tính) mới vào cụm.
- Khả năng chịu lỗi: Dữ liệu luôn được đảm bảo toàn vẹn ngay cả khi có một số node bị lỗi.
- Sẵn sàng cao: Cho phép bổ sung thêm node mới hoặc thay thế node bị hỏng mà không làm ảnh hưởng đến người dùng và các ứng dụng đang sử dụng.
- Hiệu năng cao: Có thể đọc, ghi đồng thời trên nhiều node.
Kiến trúc thiết kế
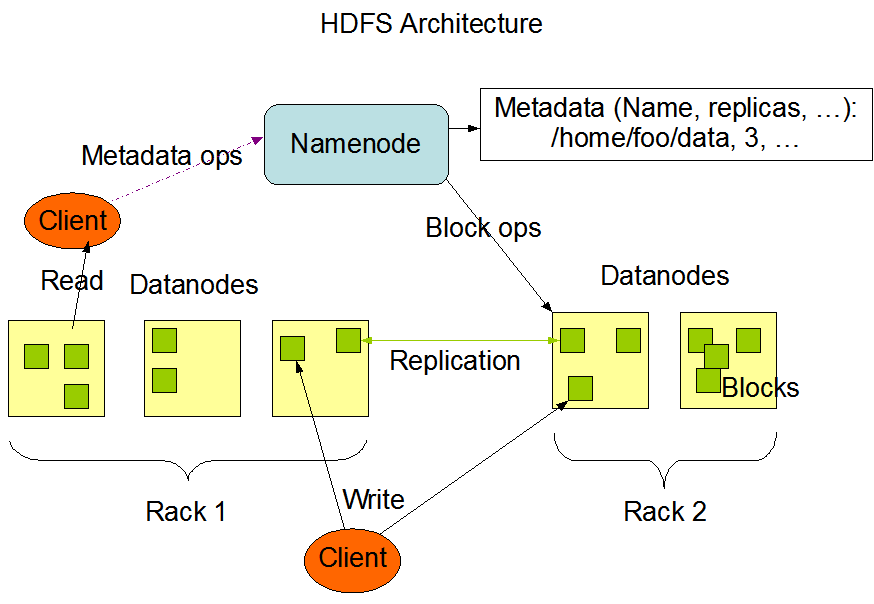
- HDFS sử dụng kiến trúc Master/Slaves. Trong cụm có một node Master gọi là Namenode đóng vai trò quản lý toàn bộ hệ thống, trên Namenode lưu trữ Metadata của hệ thống như tên file, đường dẫn, quyền truy cập, số bản sao (replicas). Các node Slaves gọi là Datanode nơi mà dữ liệu thực sự được lưu trữ.
- Blocks: Mỗi file dữ liệu trên HDFS sẽ được chia thành các block và lưu trữ trên các Datanode theo sự điều phối của Namenode. Mặc định kích thước mỗi block là 128MB, người dùng có thể thay đổi trong file cấu hình của HDFS.
- Replication: Để đảm bảo an toàn và tăng tốc độ khi đọc dữ liệu, mỗi file dữ liệu trên HDFS được lưu trữ thành nhiều bản sao trên các node khác nhau. Mặc định số bản sao là 3, người dùng có thể thay đối số lượng bản sao trong file cấu hình của HDFS trên mỗi Datanode.
Thử nghiệm với HDFS
Cài đặt
Lý thuyết như vậy thôi, giờ chúng ta đi vào thực hành với HDFS. Mình sẽ sử dụng các Docker Container đã build trong bài viết trước để thử nghiệm, bạn có thể xem lại cách build tại đây.
Đầu tiên bạn start node01 và bật bash trong container
$ docker start node01
$ docker exec -it node01 bash
Trên node01 mình sẽ xoá dữ liệu cũ trên hdfs đi và format lại
$ su hdfs
[hdfs]$ rm -rf ~/hadoop
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format
Sau khi format xong bạn sẽ thấy có thư mục
~/hadoop/dfs/nameđược tạo ra, đây là nơi sẽ lưu trữ các metadata của hệ thống.
Start Namenode và kiểm tra trên giao diện web http://localhost:9870/
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start namenode
Lúc này node01 đã trở thành Namenode, khi kiểm tra trong tab Datanodes trên giao diện web bạn sẽ không thấy có Datanode nào do chưa chạy Datanode.
Start Datanode
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start datanode
Kiểm tra lại trên giao diện web, ta sẽ thấy node01 xuất hiện trong tab Datanodes. Dữ liệu của Datanode sẽ được lưu trữ trong thư mục
~/hadoop/dfs/data. Node01 lúc này vừa là Namenode vừa là Datanode.
Tương tự bạn chạy Datanode trên node02 và node03 để được cụm 3 node.
node02
$ docker start node02
$ docker exec -it node02 bash
$ echo "127.20.0.2 node01" >> /etc/hosts # thay bang ip node01
$ su hdfs
[hdfs]$ rm -rf ~/hadoop
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start datanode
Kiểm tra trên giao diện web
http://localhost:9870/dfshealth.html#tab-datanodesẽ thấy hệ thống đã nhận đủ 3 node.
Mặc định Namenode và Datanode sẽ liên lạc với nhau sau mỗi 300s. Mình sẽ thay đổi lại cấu hình này xuống 3s để tiện cho các thử nghiệm tiếp theo.
$HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
...
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>3000</value>
</property>
</configuration>Thử nghiệm
- Đọc ghi dữ liệu trên HDFS
Copy dữ liệu vào HDFS từ node03
hdfs@node03:~$ echo "hello world" > test1.txt
hdfs@node03:~$ hdfs dfs -copyFromLocal test1.txt /
Lưu ý: khi cài đặt mình đã cấu hình
dfs.permissions.superusergroup=hadoopvàdfs.datanode.data.dir.perm=774tức là chỉ user của group hadoop mới có quyền đọc ghi trên hdfs. Nếu bạn muốn sử dụng user khác thì phải add user đó vào group hadoop trên Namenode bằng lệnhadduser [username] hadoop
Copy dữ liệu từ HDFS về node02
hdfs@node02:~$ hdfs dfs -copyToLocal /test1.txt ./
hdfs@node02:~$ cat test1.txt
hello world
Kiểm tra thông tin của File
test1.txttrên HDFS ta sẽ thấy file có 1 block và đang lưu trữ thực tế trên node03.
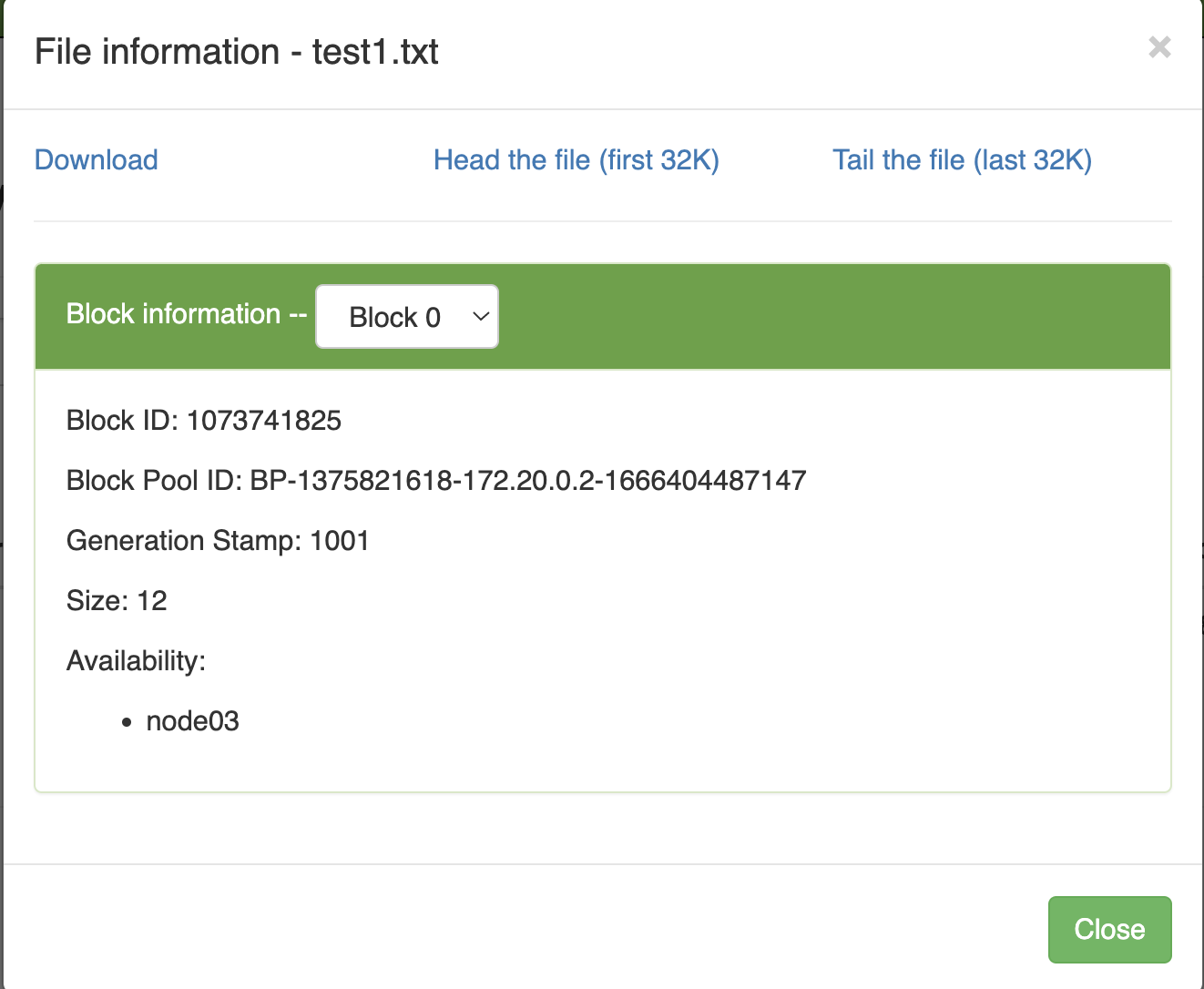
Nếu giờ ta tắt Datanode trên node03 đi thì sẽ không thể truy cập được file này từ node02 nữa.
hdfs@node03:~$ $HADOOP_HOME/bin/hdfs --daemon stop datanode
root@node02:~/install# hdfs dfs -copyToLocal /test1.txt ./
2022-10-22 12:36:57,139 WARN hdfs.DFSClient: No live nodes contain block BP-1375821618-172.20.0.2-1666404487147:blk_1073741825_1003 after checking nodes = [], ignoredNodes = null
- Ghi dữ liệu từ nhiều node vào cùng 1 file
hdfs@node02:~$ echo "data write from node2" > test2.txt
hdfs@node02:~$ hdfs dfs -appendToFile test2.txt /test1.txt
hdfs@node02:~$ hdfs dfs -cat /test1.txt
hello world
data write from node2
Khi kiểm tra thông tin ta thấy dữ liệu vẫn chỉ được lưu trữ trên 1 block của node03.
- Copy một file dữ liệu lớn hơn blocksize lên HDFS
root@node01:~/install# hdfs dfs -copyFromLocal hadoop-3.3.4.tar.gz /hadoop.tar.gz
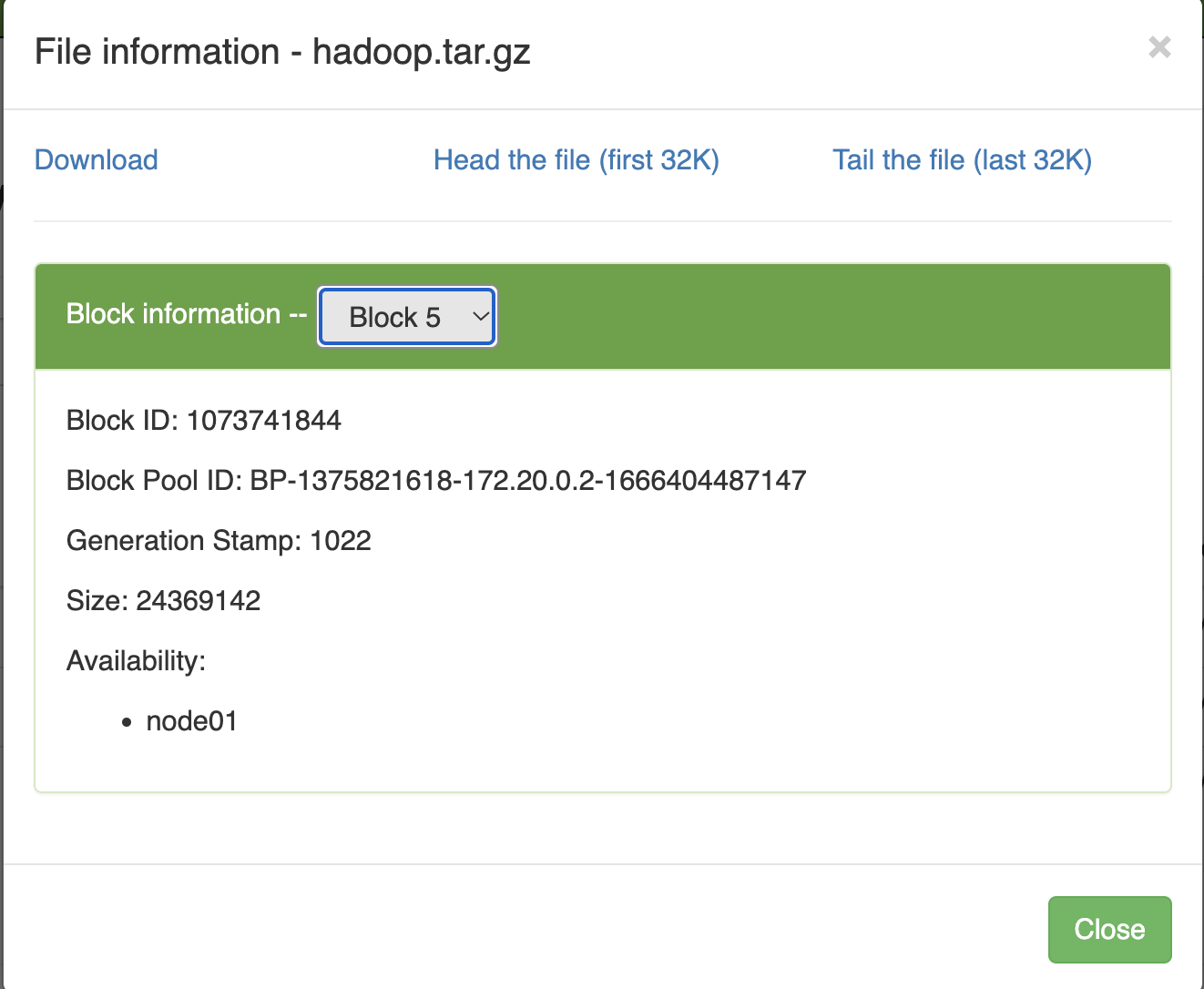
Ta thấy rằng cả 5 block của file dữ liệu này đều được lưu trữ trên node01. Nếu muốn dữ liệu được lưu trữ trên nhiều node để đảm bảo an toàn, ta cần thay đổi số replication.
root@node03:~/install# hdfs dfs -D dfs.replication=2 -copyFromLocal hadoop-3.3.4.tar.gz /hadoop_2.tar.gz
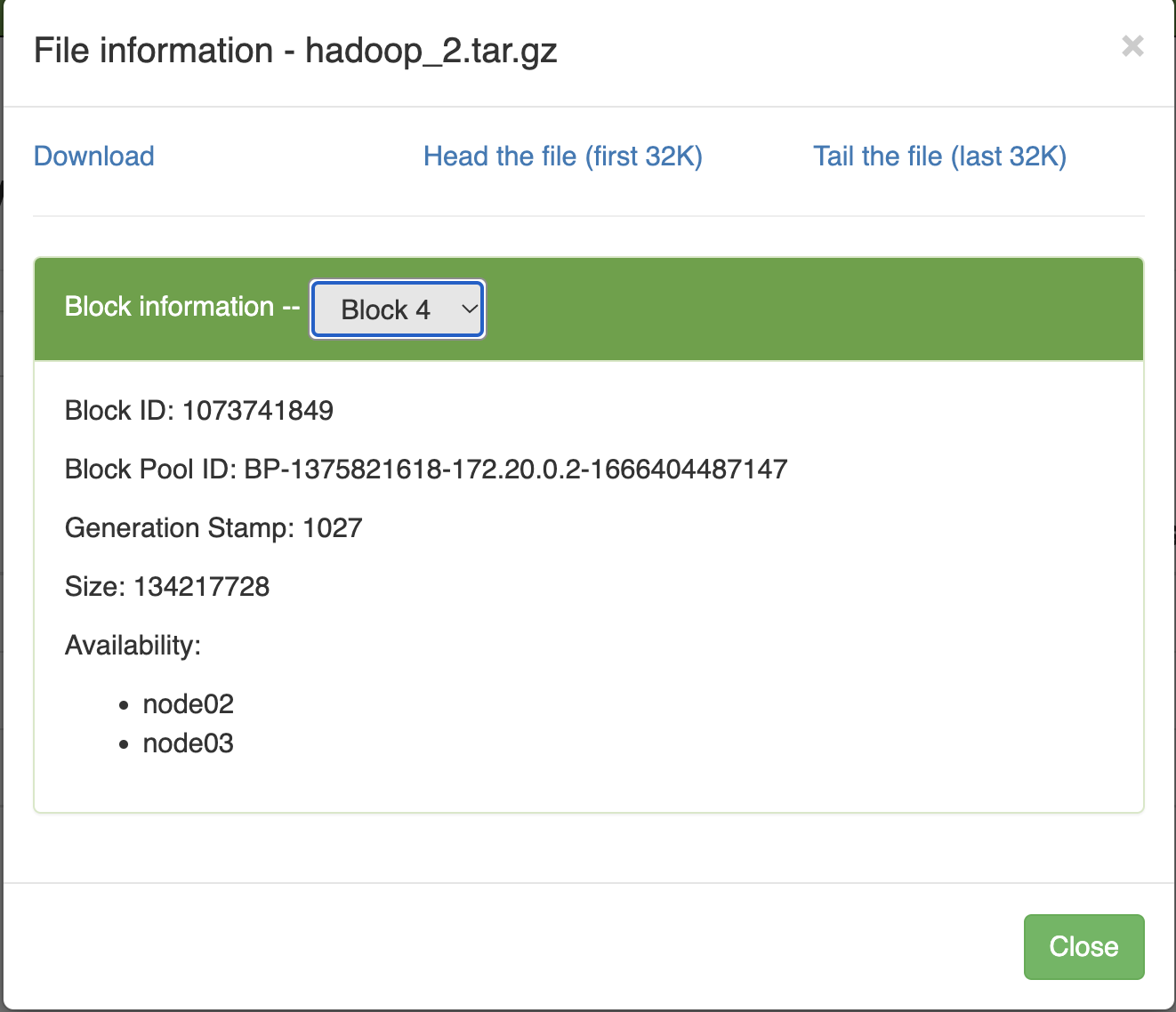
Với số replication=2 thì mỗi block của file dữ liệu được lưu trữ trên 2 node, lúc này nếu ta tắt node03 và truy vấn file từ node02 thì vẫn có thể lấy được dữ liệu
root@node02:~/install# hdfs dfs -copyToLocal /hadoop_2.tar.gz ./
root@node02:~/install# ls
hadoop-3.3.4.tar.gz hadoop_2.tar.gz test
Ta tiếp tục tắt node02 và thử truy vấn dữ liệu từ node01
root@node01:~/install# hdfs dfs -copyToLocal /hadoop_2.tar.gz ./
root@node01:~/install# ls
hadoop-3.3.4.tar.gz hadoop_2.tar.gz test
Ta thấy vẫn có thể lấy được dữ liệu về, nguyên nhân là vì số replication của file dữ liệu này là 2 nên khi node03 bị tắt, Namenode sẽ tự động tạo thêm một bản sao mới và lưu trên 2 node còn lại để đảm bảo số replication vẫn là 2, nhờ đó khi node2 bị tắt ta vẫn lấy được đầy đủ dữ liệu từ node01.
- Thử nghiệm với Namenode bị tắt
node01
$HADOOP_HOME/bin/hdfs --daemon stop namenode
node02
hdfs@node02:~$ hdfs dfs -appendToFile test2.txt /test3.txt
appendToFile: Call From node02/172.20.0.3 to node01:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
Khi Namenode bị tắt thì sẽ không thể đọc hay ghi dữ liệu được nữa, đây chính là điểm yếu của hệ thống chỉ có 1 Namenode, trong bài viết sau mình sẽ giới thiệu kiến trúc HA với nhiều hơn 1 Namenode.
- Thử nghiệm với tất cả Datanode đều bị tắt
node02
hdfs@node02:~$ hdfs dfs -copyFromLocal test2.txt /test4.txt
copyFromLocal: Cannot create file/test4.txt._COPYING_. Name node is in safe mode.
Lúc này mặc dù vẫn có thể kết nối đến Namenode nhưng cũng không thể đọc ghi dữ liệu trên HDFS được.
Kết luận
Thông qua các thử nghiệm đã thực hiện chúng ta có thể rút ra một số nhận xét sau:
- Để hệ thống HDFS có thể hoạt động được thì cần tối thiểu 1 Namenode và 1 Datanode, tuy nhiên để đáp ứng được yêu cầu về chịu lỗi thì cần có 2 Datanode và nên có 2 Namenode.
- Dữ liệu trên HDFS luôn ưu tiên lưu trữ tại địa phương thay vì các node ở xa, trường hợp Datanode trên node không chạy thì mới được chuyển sang lưu trữ ở node khác.
- Số replication nên được đặt từ 2 trở lên để khi một node gặp vấn đề thì vẫn có thể khôi phục từ các node khác.
Qua bài viết này mình đã giới thiệu các chức năng cơ bản nhất của HDFS và làm một số thử nghiệm thực tế với nó, hi vọng đã có thể giúp ích được cho bạn trong quá trình sử dụng. Hẹn gặp lại trong các bài viết sau!