DWH 2: Hệ thống phân tích dữ liệu blockchain
- 14 minsTrong bài viết trước mình đã giới thiệu với các bạn một thiết kế và cài đặt Data Warehouse dựa trên nền tảng Hadoop và một số công nghệ Opensource, bạn có thể xem lại tại đây. Trong bài viết này mình sẽ sử dụng DWH này để áp dụng cho một bài toán cụ thể là phân tích dữ liệu Blockchain. Do nội dung bài viết sẽ tập trung vào hệ thống phân tích dữ liệu nên mình sẽ không đi quá sâu vào công nghệ Blockchain mà sẽ chỉ trình bày các vấn đề liên quan đến dữ liệu EVM Blockchain để giải thích cho thiết kế của hệ thống.
Nội dung
- Sơ lược về EVM Blockchain
- Kiến trúc thiết kế
- Scanner
- Decoder
- Spellbook
- Visualization
- Automation
- Kết luận
Sơ lược về EVM Blockchain
Bitcoin cho chúng ta thấy phiên bản đầu tiên của Blockchain là một sổ cái phi tập trung (bạn có thể xem lại bài viết tại đây), nơi mà toàn bộ các giao dịch chuyển tiền được ghi lại. EVM Blockchain là thế hệ tiếp theo của Blockchain, nó bao gồm một lớp các chain ra đời sau này kể từ khi Ethereum được giới thiệu bao gồm rất nhiều chain phổ biến như: Ethereum, Binance Smart Chain, Polygon… (bạn có thể xem thêm trong danh sách này). Ethereum đã giúp cho Blockchain trở nên linh hoạt và đa dụng hơn thay vì chỉ có thể thực hiện các giao dịch chuyển tiền, mình sẽ tóm tắt lại một số điểm mới của EVM Blockchain như sau:
Smart Contract: là một chương trình đang nằm trên EVM Blockchain, tương tự như phần mềm nằm trên máy tính. Smart Contract sẽ được kích hoạt khi người dùng gọi đến một chức năng (function) của nó, lúc này Smart Contract sẽ thực thi chức năng đó theo đúng những gì mà nó được lập trình. Smart Contract thường được viết bằng ngôn ngữ Sodility, dưới đây là một ví dụ đơn giản:
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.4.16 <0.9.0;
contract SimpleStorage {
uint storedData;
function set(uint x) public {
storedData = x;
}
function get() public view returns (uint) {
return storedData;
}
}Ethereum Virtual Machine (EVM): Là máy ảo chạy trên các node của EVM Blockchain dùng để thực thi các chức năng của Smart Contract.
Native cryptocurrency: Là đồng tiền chính trên mỗi chain, ví dụ trên Ethereum là Ether (ETH), Binance Smart Chain là Binance (BNB). Native cryptocurrency được tạo ra tuỳ theo cơ chế của mỗi chain khác nhau, và được sử dụng để trả phí giao dịch trên chain đó.
Transaction: Khi người dùng thực hiện việc chuyển tiền, deploy contract (đưa một contract mới lên blockchain) hay thực hiện một chức năng của Smart Contract thì sẽ tạo ra một giao dịch.
Gas: Là đơn vị để đo lường khối lượng tính toán của EVM khi thực hiện một giao dịch. Để thực hiện được giao dịch thì người dùng phải trả phí gas cho mạng lưới.
Token Standards: Là các chuẩn cho Smart Contract cho Token, nó bao gồm các chức năng mà một Smart Contract cần phải có để đạt chuẩn, dưới dây là 3 Torken Standards phổ biến trên EVM Blockchain:
- ERC20: Là một chuẩn token rất giống với Native Cryptocurrency tức là bạn có thể lưu trữ nó trong ví, thực hiện chuyển token, điểm khác biệt là ERC20 được tạo ra từ Contract nên nó linh hoạt và đa dụng hơn nhiều so với Native Cryptocurrency. Các Stable Coin (Token có giá được neo với một đồng tiền pháp định: VD USDT, BUSD…), Wrap Token (Token thay thế cho Native Cryptocurrency vd: WBNB, WBTC…) đều thuộc ERC20.
- ERC721: Là chuẩn token của NFT (Non-fungible Token), mỗi token của một contract là khác biệt nhau và không thay thế được cho nhau, được dùng để định danh tài sản số.
- ERC1155: Cũng là chuẩn token của NFT tuy nhiên mỗi token của một contract có thể chia nhỏ được.
Blockchain Explorer Để có thể hiểu được những gì đã, đang diễn ra trên EVM Blockchain chúng ta cần sử dụng Blockchain Explorer là một trang web cho phép người dùng tra cứu thông tin, xem dữ liệu trên blockchain một cách thân thiện hơn. VD: etherescan.io, bscscan.com, polygonscan.com…
Kiến trúc thiết kế
Để thiết kế hệ thống này mình có tham khảo những mô tả của Dune Analyst một startup cung cấp hạ tầng phân tích dữ liệu Blockchain, được định giá tới 1 tỷ đô vào thời điểm tháng 2/2022.
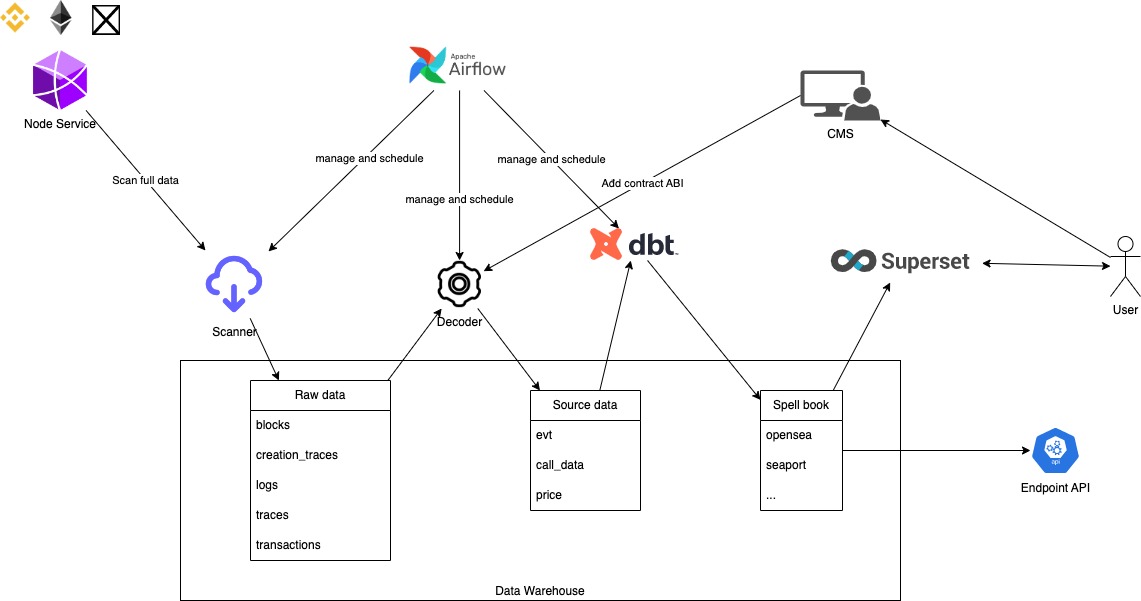
- Scanner: Có chức năng quét dữ liệu từ EVM blockchain thông qua Node service và lưu trữ dữ liệu raw vào DWH.
- Decoder: Dữ liệu raw trên EVM blockchain là dữ liệu đã được mã hoá do đó Decoder đóng vai trò giải mã dữ liệu raw thành dữ liệu Source data có cấu trúc để dễ dàng sử dụng.
- Spellbook: Là một tập hợp các bảng dữ liệu được công khai bởi Dune để phục vụ mục đích phân tích dữ liệu trên EVM blockchain, bạn có thể tham khảo source code của Spellbook tại đây
- Các thành phần khác như: DBT, Airflow, Superset mình đã giới thiệu trong bài viết trước, bạn có thể xem lại tại đây.
Scanner
Trước khi nói về Scanner mình sẽ mô tả qua một chút về dữ liệu trên EVM Blockchain. Mình sẽ lấy một ví dụ là một giao dịch Transfer của USDT, một stable coin chuẩn ERC20 trên mạng Ethereum. Ở tab overiew bạn có thể nhìn thấy các thông tin sau (click vào more detail để xem toàn bộ thông tin):
- Transaction Hash: là định danh duy nhất của transaction này, bạn có thể sử dụng TxHash để tìm chính xác transaction.
- Status: Trạng thái của giao dịch thường là Success hoặc Pending
- Block: Blocknumber của transaction, cho biết transaction này được đóng trong block nào.
- From: Địa chỉ ví của thực hiện transaction
- To: Địa chỉ nhận yêu cầu, ở đây chính là địa chỉ contract của token USDT.
- Value: số ETH (Native cryptocurrency) được gửi đến cho contract.
- Transaction fee: Phí giao dịch tính bằng ETH
- Gas Price: Giá gas tại thời điểm giao dịch tính bằng ETH
- Gas Limit & Usage: Số gas tối đa và số gas đã sử dụng cho transaction
- Burnt & Txn Savings Fees: Số ETH bị burn và số eth được trả lại cho validator khi thực hiện giao dịch. Bạn có thể xem thêm về cơ chế mint burn của ethereum tại đây.
- Input Data: dữ liệu được gửi kèm khi thực hiện giao dịch, trong giao dịch này chính là lời gọi thực hiện chức năng transfer của contract. Bạn có thể click vào View input as Original để xem dữ liệu dạng raw hoặc Decode input data để xem dữ liệu sau khi giải mã.
Chuyển qua tab logs bạn sẽ nhìn thấy danh sách các log được phát ra khi thực hiện giao dịch này, mỗi event log bao gồm các thông tin sau:
- Address: địa chỉ contract phát ra event log này, ở đây chính là contract của token USDT
- Name: Tên của event log
- Topics: chứa các thông tin được đánh index trong event log, trong đó topic[0] là signature (định danh duy nhất) của event log này, dùng để phân biệt event này với event khác.
- Data: Dữ liệu trong event log.
Scanner sẽ thực hiện việc lấy dữ liệu raw transaction và event log từ Node Service và lưu xuống DWH, mình sử dụng thư viện Web3j để lấy lấy dữ liệu từ Node Service. Dưới đây là một đoạn code mẫu bằng ngôn ngữ Scala để các bạn tham khảo:
import org.web3j.protocol.Web3j
import com.google.gson.Gson
val rpcUrl = <URL_YOUR_RPC_SERVICE>
val web3 = Web3j.build(new HttpService(rpcUrl))
val gson = new Gson()
val blockNumber = new DefaultBlockParameterNumber(1234)
val query = new EthFilter(blockNumber, blockNumber, java.util.Collections.emptyList[String]())
val eventlogs = gson.toJson(web3.ethGetLogs(query).sendAsync().get().getLogs)
println(eventlogs)
val blockData = web3.ethGetBlockByNumber(blockNumber, true).sendAsync().get().getBlock
val transactions = gson.toJson(blockData)
println(transactions)
Với số lượng block cần lấy dữ liệu là rất lớn: 16,6 triệu block trên Ethereum và 25,6 triệu block trên BSC nên để có thể sử dụng được tối đa số lượng request đến Node Service, mình sử dụng Spark để thực hiện việc scan nhiều block song song với nhau.
Kết quả chạy đến thời điểm hiện tại như sau:
- Dữ liệu Event Log:
- BSC Chain:
- Số block: 23490000
- Dung lượng: 1,2 TB
- ETH chain:
- Số block: 16230000
- Dung lượng: 325.6 GB
- BSC Chain:
- Dữ liệu Transaction:
- BSC Chain:
- Số block: 18900000
- Dung lượng: 1,2 TB
- BSC Chain:
Decoder
Dữ liệu sau khi được lấy về là dữ liệu raw đã được mã hoá, để giải mã được nó ta cần có ABI (Application Binary Interface) của contract. ABI giống như một bản hướng dẫn kỹ thuật cho phép chúng ta có thể decode được dữ liệu raw thành dữ liệu có cấu trúc và mang ý nghĩa rõ ràng phù hợp cho việc phân tích. Chi tiết về ABI các bạn có thể xem tại đây. Để lấy được ABI của contract chúng ta có thể sử dụng Blockchain Explorer, ví dụ với contract token USDT bạn có thể vào đây, trong trang này bạn có thể nhìn thấy cả mã nguồn và ABI của contract. Decoder được thiết kế bao gồm CMS cho phép người dùng upload file ABI của contract (do không phải contract nào cũng có ABI đầy đủ trên Explorer), decoder sẽ giải mã dữ liệu raw và đẩy vào decoded table, bạn có thể xem mô tả về decoded table tại đây. Dưới đây là một đoạn code mẫu decode dữ liệu event log và function call data để các bạn tham khảo:
import com.esaulpaugh.headlong.abi.{Event, Function}
import com.esaulpaugh.headlong.util.Strings
import org.web3j.abi.EventEncoder
import java.util
val eventABIJson = <String abi json of one event>
val e = Event.fromJson(eventABIJson)
val eventSignature = EventEncoder.buildEventSignature(e.getCanonicalSignature)
println(eventSignature)
val topic1, topic2, topic3, topic4: String // Topics of one Event
val data: String // Data of one Event
val topics = new util.ArrayList[Array[Byte]]
topics.add(Strings.decode(topic1.replace("0x", "")))
if (topic2 != null && topic2 != "") {
topics.add(Strings.decode(topic2.replace("0x", "")))
}
if (topic3 != null && topic3 != "") {
topics.add(Strings.decode(topic3.replace("0x", "")))
}
if (topic4 != null && topic4 != "") {
topics.add(Strings.decode(topic4.replace("0x", "")))
}
val extractedData = e.decodeArgs(topics.toArray(new Array[Array[Byte]](topics.size())), Strings.decode(data.replace("0x", "")))
println(extractedData)
val functionABIJson = <String abi json of one Function>
val f = Function.fromJson(functionABIJson)
val methodId = Strings.encode(f.selector())
println(methodId)
val data: String // Input of one Transaction
val extractedData = f.decodeCall(Strings.decode(data.replace("0x", "")))
println(extractedData)
Spellbook
Sau khi lấy source code của Spellbook về bạn tiến hành cài đặt theo hướng dẫn tại đây, kiểm tra doc của Spellbook trên giao diện:
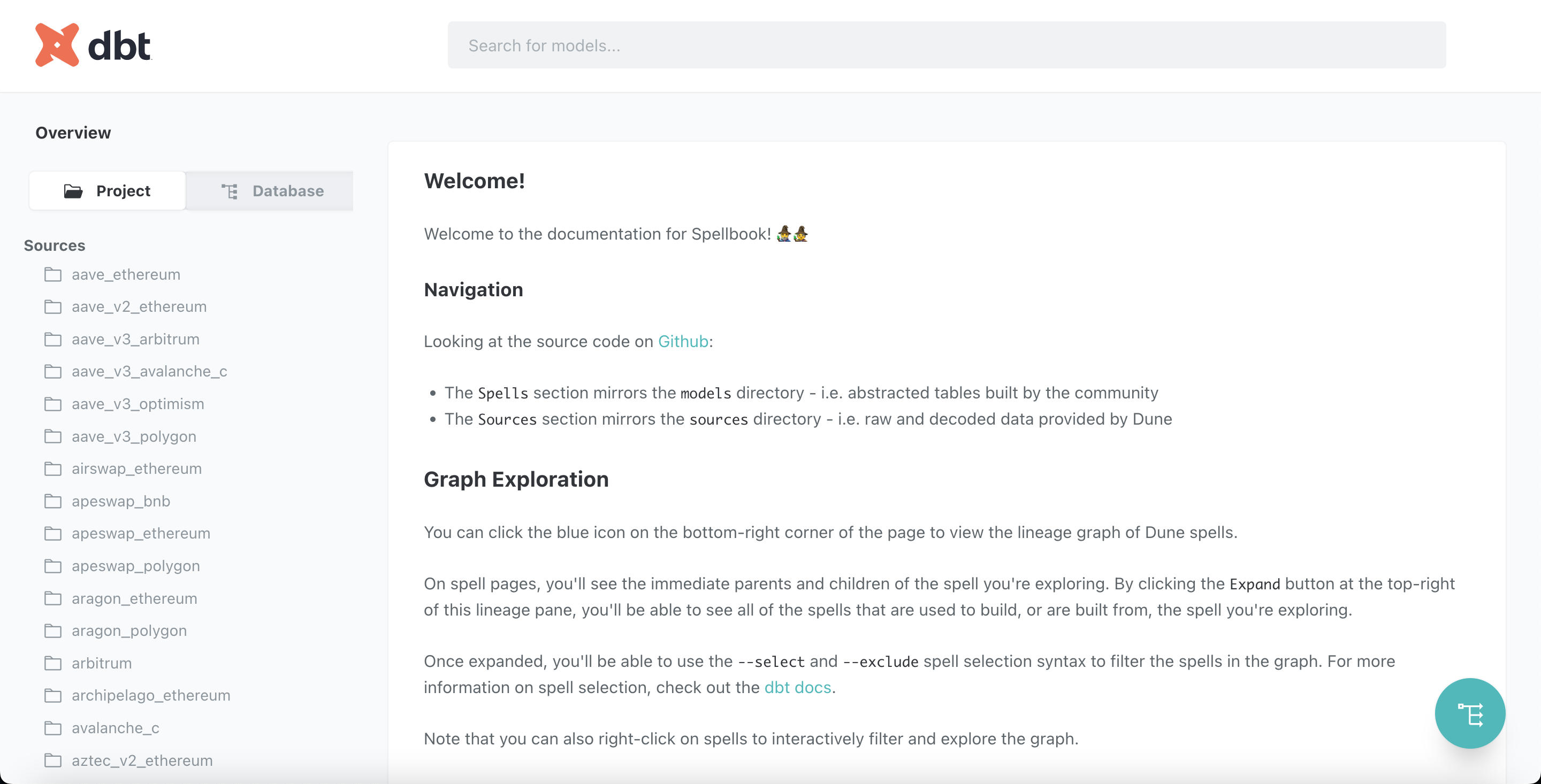
Để chạy riêng từng bảng trên Spellbook bạn dùng command sau:
$ dbt run --select +<model_name>
Trước khi chạy một model bạn cần phải kiểm tra các bảng dữ liệu mà nó phụ thuộc vào đã có đủ hay chưa bằng cách kiểm tra DAG Graph của model đó. Ví dụ mình muốn chạy model: tofu_bnb_trades có DAG Graph như sau:
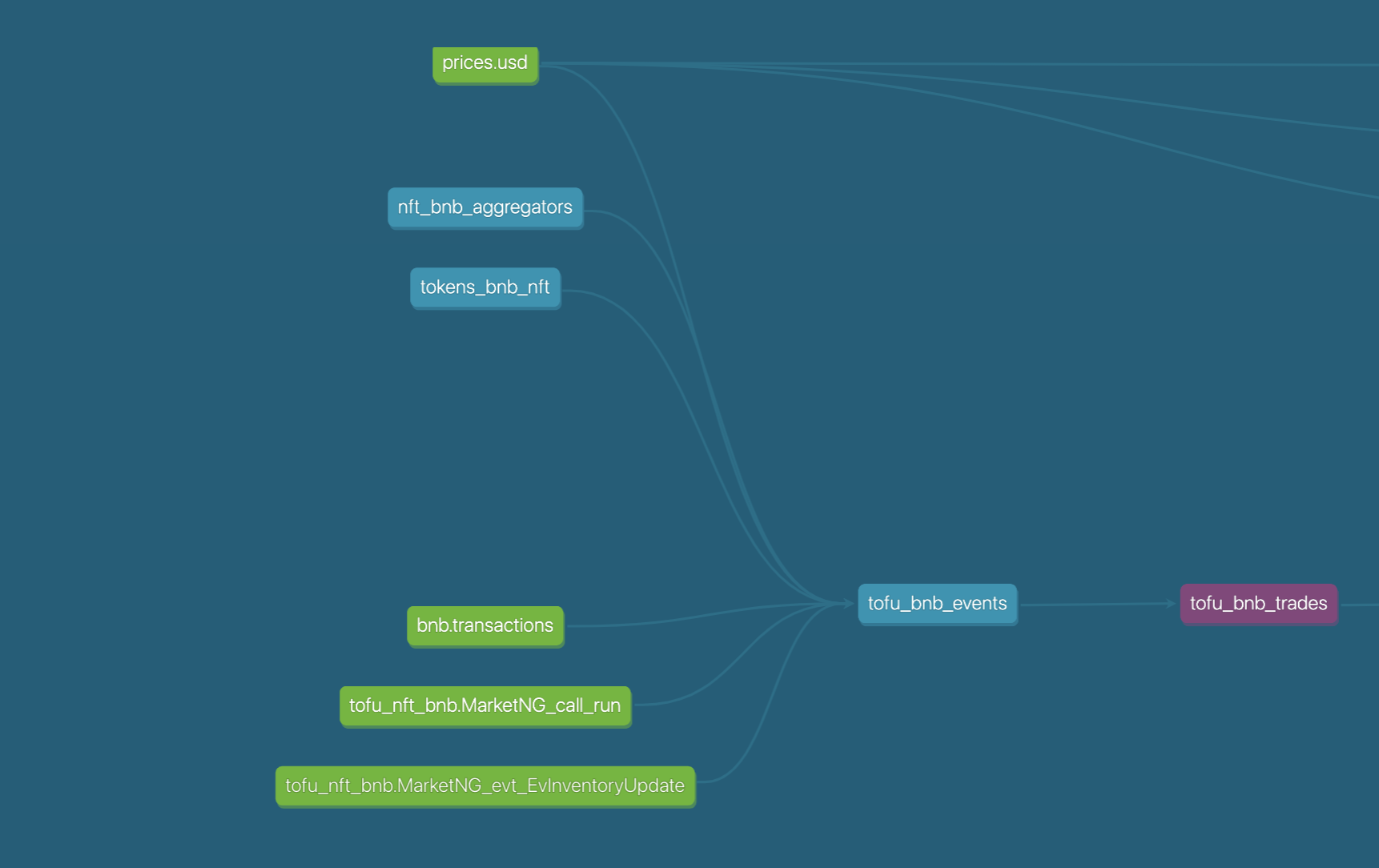
Ta thấy rằng model này đang phụ thuộc vào các datasource (green) vì vậy ta cần chuẩn bị các bảng dữ liệu datasource (bằng cách sử dụng Decoder hoặc lấy thêm dữ liệu từ nguồn khác) trước khi có thể chạy được model này.
Kết luận
Bài viết hôm nay đến đây thôi, mình sẽ tiếp tục viết thêm nội dung cho cho bài viết này trong các lần cập nhật tiếp theo nhé. Hẹn gặp lại các bạn
![]() Hiện tại mình đang phát triển một số kênh phân tích dữ liệu blockchain hàng ngày trên nền tảng chainslake.com:
Hiện tại mình đang phát triển một số kênh phân tích dữ liệu blockchain hàng ngày trên nền tảng chainslake.com:
- https://chainslake.com/@bitcoin
- https://chainslake.com/@ethereum
- https://chainslake.com/@binance
- https://chainslake.com/@aave
- https://chainslake.com/@nftfi
- https://chainslake.com/@opensea
- https://chainslake.com/@uniswap
Chainslake là nền tảng phân tích dữ liệu blockchain hoàn toàn miễn phí, do mình phát triển dựa trên những kiến thức được trình bày trong chính blog này. Rất mong sự ủng hộ từ các bạn.