Hệ thống thu thập dữ liệu thông minh - AI Paser Crawler
- 12 minsChào mọi người, mình đã trở lại rồi đây! Mình rất cảm ơn mọi người thời gian qua đã ủng hộ blog của mình, những góp ý và thắc mắc của các bạn chính là nguồn động lực to lớn đối với mình. Bài viết hôm nay khá là đặc biệt, mình sẽ giới thiệu cho mọi người về một dự án mà mình rất tâm huyết: AI Parser Crawler (APC) - Hệ thống thu thập dữ liệu thông minh, hi vọng mọi người sẽ cảm thấy thích nó.
APC được thiết kế để crawl dữ liệu từ nhiều website mà không cần biết trước cấu trúc, có khả năng tự động nhận diện các trang có dữ liệu mục tiêu, tự động trích xuất thông tin cần thiết trên trang. Trong giới hạn bài viết này mình sẽ trình bày tóm tắt những ý tưởng chính, thiết kế và kinh nghiệm khi triển khai dự án, nếu bạn đọc quan tâm và muốn tìm hiểu sâu hơn thì có thể tham khảo luận văn của mình tại đây
Nội dung
Giới thiệu tổng quan
Ý tưởng cho dự án này xuất hiện khi mình cần maintain một con Crawler dựa trên Scrapy, thu thập dữ liệu từ các trang tin rao bất động sản, sử dụng css selector và xpath parser để trích rút các thông tin từ tin rao như địa chỉ, giá, diện tích, số phòng… Hệ thống đang có gặp một số vấn đề như sau:
- Mỗi website được xử lý bằng 1 Spider với một bộ parser bóc tách dữ liệu riêng, nếu muốn thu thập thêm từ website khác thì phải code thêm Spider mới.
- Khi website thay đổi giao diện, cấu trúc thay đổi sẽ khiến Spider buộc phải thay đổi code để đáp ứng.
- Nếu có nhu cầu trích xuất thêm thông tin thì sẽ phải sửa trên toàn bộ các Spider.
Để giải quyết các vấn đề trên thì ý tưởng của APC là bổ sung thêm một số chức năng như sau:
- Phân loại để nhận biết các trang có dữ liệu mục tiêu trước cả khi load trang (phân loại theo URL)
- Bộ Parser trích rút thông tin không cần sử dụng selector hay xpath, không phụ thuộc vào cấu trúc của trang.
Dự án đã được mình triển khai trong 2 sản phẩm ở 2 công ty khác nhau, một ở Cenhomes.vn với bài toán thu thập dữ liệu từ nhiều website bất động sản, một ở Darenft với bài toán tổng hợp so sánh giá listing của 1 NFT trên nhiều chợ. Mỗi bài toán có những yêu cầu cụ thể khác nhau tuy nhiên vẫn sử dụng chung về ý tưởng, giải pháp và thiết kế, cùng một số công nghệ opensource như Fasttext, Web2text, Fonduer.
Phân tích giải pháp
Nhận biết trang mục tiêu
Trong hệ thống crawler bằng Scrapy, crawler sẽ sử dụng các luật được định nghĩa bởi lập trình viên để xác định một URL có có chứa dữ liệu mục tiêu hay không, các luật này sẽ được fix cứng trong code cho từng website (gọi là Spider). Trong hệ thống APC, mình sử dụng 2 mô hình học máy để xác định trang mục tiêu:
- Content Classification Model: Mô hình phân loại trang dựa trên nội dung, có thể thực hiện việc phân loại trên nhiều website khác nhau.
- Input: Title, Description, Main text trong trang
- Ouput: Kết quả phân loại trang
- Cách train mô hình: Dữ liệu dùng để train được thu thập từ nhiều website khác nhau, mỗi trang chỉ lấy title, description và main text. Dữ liệu được gán nhãn bằng cách sử dụng các luật phân loại có thể áp dụng trên từng website, kết quả sẽ được một bộ dữ liệu có gán nhãn để train mô hình. Mình sử dụng thư viện Fasttext để train mô hình này, độ chính xác F1 score cần đạt trên 90%.
- Trường hợp sử dụng: Mô hình phân loại trang dựa trên nội dung tuy có thể thực hiện việc phân loại trên nhiều website khác nhau nhưng có nhược điểm là phải load trang về mới có thể phân loại được, do đó mô hình này được sử dụng để tạo dữ liệu huấn luyện cho mô hình phân loại URL.
- URL Classification Model: Mô hình phân loại trang dựa trên URL, được train riêng cho từng website
- Input: URL của trang
- Output: Kết quả phân loại trang
- Cách train mô hình: Dự liệu train lấy từ các trang 1 website, sử dụng mô hình phân loại dựa trên nội dung để phân loại và gán nhãn cho các trang sau đó sử dụng kết quả gán nhãn để train mô hình phân loại URL. Đối với mô hình này thì tùy thuộc vào từng trường hợp cụ thể để lựa chọn giải pháp phù hợp. Đối với bài toán ở Cenhomes.vn mình tiếp tục sử dụng Fasttext để train mô hình, còn với bài toán ở DareNFT mình đã viết một thuật toán để sinh ra pattern url cho website.
- Trường hợp sử dụng: Mô hình phân loại trang dựa trên URL được sử dụng riêng để phân loại URL cho từng website, APC sử dụng nó để biết trước URL nào chứa dữ liệu mục tiêu từ đó định hướng việc thu thập.
Trích rút thông tin từ trang
Bộ parser truyền thống trong Scrapy yêu cầu lập trình viên phải định nghĩa luật bóc tách dữ liệu cho từng website, điều này khiến việc mở rộng thu thập dữ liệu trên nhiều website trở nên khó khăn. Để trích xuất thông tin, APC sử dụng 2 mô hình học máy:
- Main content Detection Model: Mô hình phát hiện nội dung chính trong trang. Trong 1 trang thường có nhiều thành phần như header, footer, slidebar và main, trong đó chỉ có phần main là chứa nội dung có ích cho việc trích xuất thông tin, thêm vào đó việc trích rút thông tin từ phần main thay vì toàn bộ trang sẽ giúp giảm thiểu nhầm lẫn thông qua việc giảm bớt dữ liệu nhiễu. Mô hình xác định nội dung chính có thể hoạt động trên nhiều website khác nhau.
- Input: HTML của toàn bộ trang
- Output: Main html và main text của trang
- Cách train mô hình: Dữ liệu train lấy từ nhiều website khác nhau, với mỗi website sử dụng css selector hoặc xpath để đánh dấu phần main (gán nhãn dữ liệu) sau đó mình sử dụng Web2text để train mô hình với độ chính xác từ 75-80%
- Trường hợp sử dụng: Mô hình xác đinh main content có thể hoạt động trên nhiều website khác nhau tuy nhiên nó có một vấn đề là chạy rất chậm do đó mình ko sử dụng trực tiếp mô hình này khi crawl dữ liệu, thay vào đó mình sử dụng nó để phát hiện main content cho từng website dưới dạng xpath hoặc css selector rồi sử dụng nó lấy main khi crawl dữ liệu.
- Information Extraction Model: Mô hình này cho phép trích rút các thông tin theo yêu cầu bài toán. Ví dụ: địa chỉ, giá, diện tích… trong bài toán thu thập dữ liệu bất động sản
- Input: Main html của trang
- Ouput: các thông tin trích xuất được theo format Json
- Cách train mô hình: Dữ liệu huấn luyện lấy từ kết quả trích xuất main content của các trang mục tiêu. Mình sử dụng framework Fonduer và phương pháp Weak supervise learning để gán nhãn và train mô hình, nói một cách đơn giản thì đây là một vòng lặp bao gồm nhiều bước từ gán nhãn -> train mô hình -> đánh giá -> điều chỉnh để dần dần nâng cao độ chính xác của mô hình và tiết kiệm chi phí cho việc gán nhãn dữ liệu. Chi tiết về cách làm bạn có thể đọc trong luận văn của mình nhé.
- Trường hợp sử dụng: Mô hình trích rút thông tin không được tích hợp trực tiếp trong Crawler, thay vào đó mình đặt nó trong bước tiền xử lý dữ liệu, điều này cho phép Crawler lưu trữ trực tiếp phần main html, main text trong Datawarehouse và công đoạn trích rút thông tin được xem như 1 bước transform dữ liệu trong DWH.
Kiến trúc thiết kế
APC gồm có 2 thành phần chính:
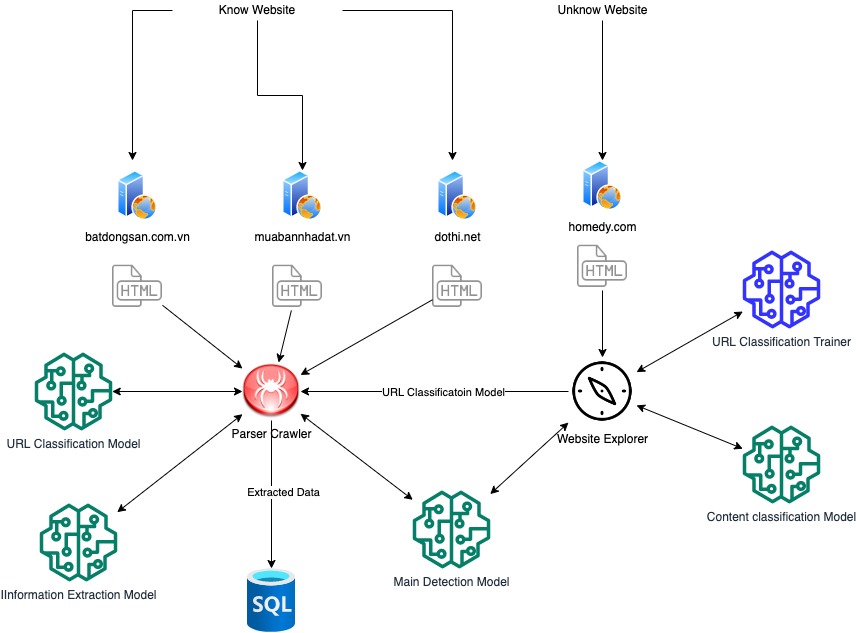
- Website Explorer: Có nhiệm vụ khảo sát và lấy dữ liệu từ website mới được người dùng thêm vào, từ đó train mô hình phân loại trang dựa trên URL cho website đó.
- Parser Crawler: Có nhiệm vụ crawl dữ liệu từ các website mà hệ thống đã biết, sử dụng các mô hình để lựa chọn và trích xuất dữ liệu từ các trang mục tiêu trong website.
Dưới đây là sơ đồ luồng hoạt động của APC bao gồm 2 pharse:
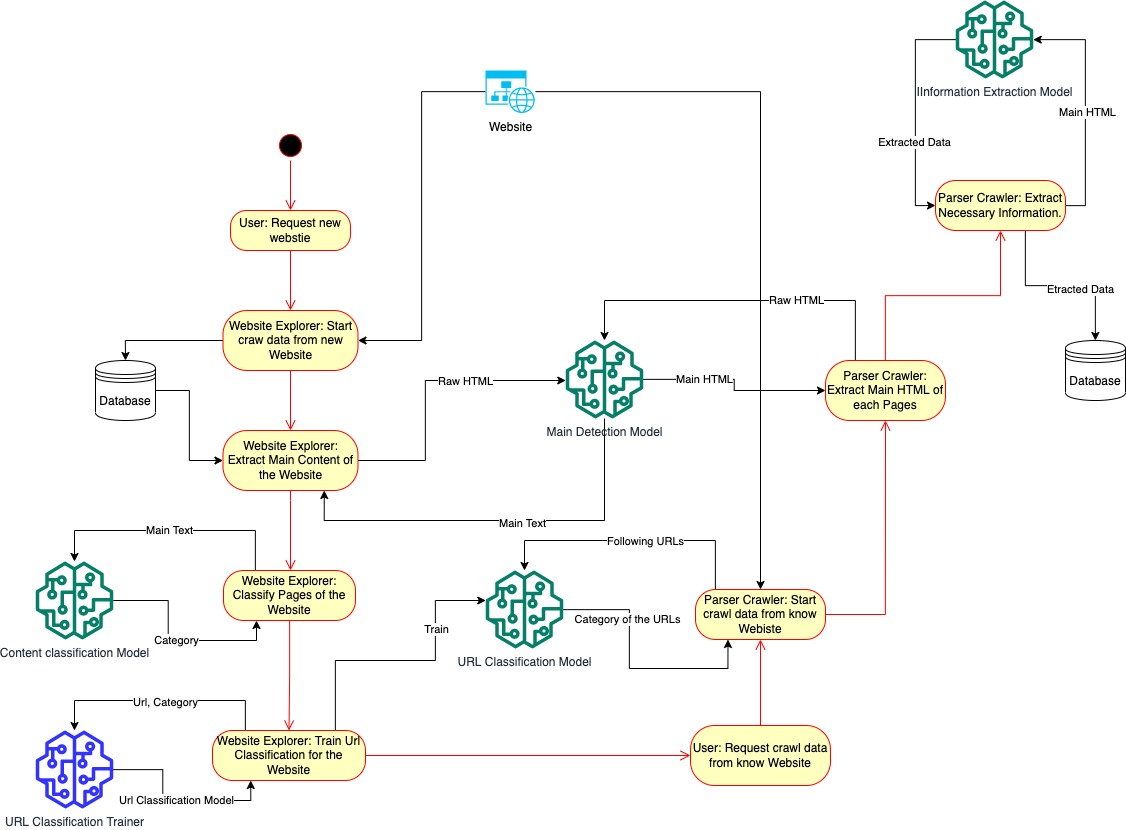
- Pharse 1: Khảo sát website mới
- Khi người dùng có nhu cầu muốn crawl dữ liệu từ một trang web mới, họ sẽ add URL gốc của trang web vào Website Explorer.
- Website explorer sẽ tiến hành thu thập dữ liệu từ website mới (sử dụng thuật toán quét theo chiều rộng để lấy được đa dạng các loại trang trên website), sau khi đạt đủ số lượng trang nhất định nó sẽ dừng thu thập và chuyển đến bước tiếp theo.
- Với những dữ liệu (HTML thô) đã thu được từ website mới, Website explorer sẽ phân loại chúng sử dụng mô hình main detection và mô hình content classification.
- Kết quả phân loại của mỗi trang cùng với URL tương ứng sẽ được sử dụng để train mô hình phân loại URL cho website mới. Mô hình sau đó sẽ được lưu trữ để sử dụng, lúc này website mới đã sẵn sàng để chuyển sang bước crawl dữ liệu.
- Pharse 2: Crawl dữ liệu
- Người dùng bắt đầu crawl dữ liệu từ 1 website đã được khảo sát
- Parser Crawler tiến hành lấy dữ liệu từ website, sử dụng mô hình phân loại URL để phân loại trang, từ đó biết được trang nào có dữ liệu mục tiêu để tiến hành thu thập và ưu tiên lấy dữ liệu.
- Với mỗi trang mục tiêu, Parser crawler sử dụng mô hình main detection để trích xuất phần main html và main text sau đó lưu trữ chúng trong Data warehouse (hoặc database), đồng thời cũng sử dụng mô hình trích xuất thông tin để bóc tách nội dung từ main và lưu vào cơ sở dữ liệu.
Một số kinh nghiệm rút ra
Trong quá trình thực hiện dự án mình cũng có rút ra được một số kinh nghiệm, hi vọng có thể giúp ích cho bạn đọc nếu muốn xây dựng một sản phẩm tương tự:
- Nên thu thập dữ liệu từ nhiều website khác nhau để có dữ liệu huấn luyện đa dạng hơn.
- Để giảm thiểu công sức cho việc gán nhãn dữ liệu, nên tận dụng tối đa các đặc trưng cấu trúc bằng cách thực hiện việc gán nhãn trên từng website, sử dụng luật với sự hỗ trợ của css selector hoặc xpath.
- Khi train mô hình chú ý chia dữ liệu tập train và test với các website khác nhau.
- Theo kinh nghiệm của mình thì đối với các mô hình cần hoạt động với nhiều website (bao gồm cả website chưa biết) ta chỉ nên sử dụng các đặc trưng văn bản, không nên sử dụng đặc trưng cấu trúc do rất dễ gặp phải hiện tượng overfiting trên các website nằm trong tập train.
- Nên lưu trữ lại phần main html và main text và coi việc trích rút thông tin như là một công đoạn transform dữ liệu trên DWH, điều này cho phép chúng ta có thể thực hiện việc bóc tách lại thông tin từ đó tạo điều kiện để cải thiện mô hình về sau.
Kết luận
Trên đây là phần tóm tắt sơ lược về ý tưởng, thiết kế và những kinh nghiệm của mình trong quá trình thực hiện APC, nếu bạn đọc quan tâm hoặc có thắc mắc gì có thể liên hệ trực tiếp với mình nhé. Cảm ơn mọi người!