Hướng dẫn cài Hadoop cluster trên ubuntu 20.04
- 9 minsApache Hadoop là một dự án phần mềm nguồn mở được sử dụng để xây dựng các hệ thống xử lý dữ liệu lớn, cho phép tính toán phân tán và mở rộng trên các cụm tới hàng ngàn máy tính với khả năng sẵn sàng và chịu lỗi cao. Hiện nay Hadoop đã phát triển trở thành một hệ sinh thái với rất nhiều sản phẩm, dịch vụ khác nhau. Trước đây mình sử dụng Ambari HDP để cài đặt và quản lý Hadoop Ecosystem, công cụ này cho phép tập trung tất cả cấu hình của các dịch vụ Hadoop về một nơi, từ đó dễ dàng quản lý và mở rộng node khi cần. Tuy nhiên từ năm 2021 HDP đã đóng lại để thu phí, tất cả các repository đều yêu cầu tài khoản trả phí để có thể download và cài đặt. Gần đây mình có nhu cầu cần cài đặt hệ thống Hadoop mới, mình quyết định cài tay từng thành phần, tuy sẽ phức tạp và tốn nhiều công sức hơn nhưng mình có thể kiểm soát dễ dàng hơn không bị phụ thuộc vào bên khác, một phần cũng do hệ thống mới chỉ có 3 node nên khối lượng công việc cũng không bị thêm quá nhiều. Toàn bộ quá trình cài đặt mình sẽ ghi chép lại chi tiết trong series các bài viết thuộc chủ đề bigdata mọi người chú ý đón đọc nhé!
Nội dung
- Mục tiêu
- Cài đặt môi trường
- Download hadoop và cấu hình
- Chạy trên 1 node
- Thêm node mới vào cụm
- Hướng dẫn sử dụng cơ bản
- Kết luận
Mục tiêu
Trong bài viết này mình sẽ cài đặt Hadoop bản mới nhất (3.3.4 vào thời điểm viết bài này) trên 3 node Ubuntu 20.04 và OpenJdk11. Để thuận tiện cho việc setup và thử nghiệm mình sẽ sử dụng Docker để giả lập 3 node này.
Cài đặt môi trường
Đầu tiên chúng ta tạo một bridge network mới trên Docker (Nếu chưa cài Docker các bạn xem hướng dẫn cài tại đây)
$ docker network create hadoop
Tiếp theo là tạo một container trên image Ubuntu 20.04
$ docker run -it --name node01 -p 9870:9870 -p 8088:8088 -p 19888:19888 --hostname node01 --network hadoop ubuntu:20.04
Mình đang sử dụng MacOS nên cần binding port từ container ra máy host, bạn không cần làm điều này nếu sử dụng Linux hoặc Window.
Cài đặt các package cần thiết
$ apt update
$ apt install -y wget tar ssh default-jdk
Tạo user hadoop
$ groupadd hadoop
$ useradd -g hadoop -m -s /bin/bash hdfs
$ useradd -g hadoop -m -s /bin/bash yarn
$ useradd -g hadoop -m -s /bin/bash mapred
Vì lý do bảo mật, Hadoop khuyến nghị mỗi dịch vụ nên chạy trên một user khác nhau, xem chi tiết tại đây
Tạo ssh-key trên mỗi user
$ su <username>
$ ssh-keygen -m PEM -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
Start ssh service
$ service ssh start
Thêm hostname trong file /etc/hosts
172.20.0.2 node01
Lưu ý
172.20.0.2là ip container trên máy của mình, bạn thay bằng ip máy của bạn.
Kiểm tra xem đã ssh được vào hay chưa
$ ssh <username>@node01
Download hadoop và cấu hình
Ta lên trang chủ download của Hadoop tại đây để lấy link down bản mới nhất.
$ wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
$ tar -xvzf hadoop-3.3.4.tar.gz
$ mv hadoop-3.3.4 /lib/hadoop
$ mkdir /lib/hadoop/logs
$ chgrp hadoop -R /lib/hadoop
$ chmod g+w -R /lib/hadoop
Tiếp theo cần cấu hình biến môi trường, ở đây chúng ta sẽ thêm các biến môi trường vào file /etc/bash.bashrc để tất cả các user trên hệ thống đều có thể sử dụng
export JAVA_HOME=/usr/lib/jvm/default-java
export HADOOP_HOME=/lib/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HDFS_NAMENODE_USER="hdfs"
export HDFS_DATANODE_USER="hdfs"
export HDFS_SECONDARYNAMENODE_USER="hdfs"
export YARN_RESOURCEMANAGER_USER="yarn"
export YARN_NODEMANAGER_USER="yarn"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
Cập nhật biến môi trường
$ source /etc/bash.bashrc
Cũng cần cập nhật biến môi trường trong file: $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/default-java
Thiết lập cấu hình cho Hadoop
-
$HADOOP_HOME/etc/hadoop/core-site.xmlxem full cấu hình tại đây
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/${user.name}/hadoop</value>
</property>
</configuration>
/home/${user.name}/hadooplà thư mục mình lưu dữ liệu trên HDFS, bạn có thể đổi sang thư mục khác nếu muốn.
-
$HADOOP_HOME/etc/hadoop/hdfs-site.xmlxem full cấu hình tại đây
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>774</value>
</property>
</configuration>Cấu hình
dfs.replicationthiết lập số bản sao thực tế được lưu trữ đối với một dữ liệu trên HDFS.
-
$HADOOP_HOME/etc/hadoop/yarn-site.xmlxem full cấu hình tại đây
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>-1</value>
</property>
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>
</configuration>Chạy trên 1 node
Format file trên Name Node
$ su hdfs
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format
$ exit
Chạy các dịch vụ của Hadoop trên account root
$ $HADOOP_HOME/sbin/start-all.sh
Kết quả
-
http://localhost:9870/hoặchttp://172.20.0.2:9870/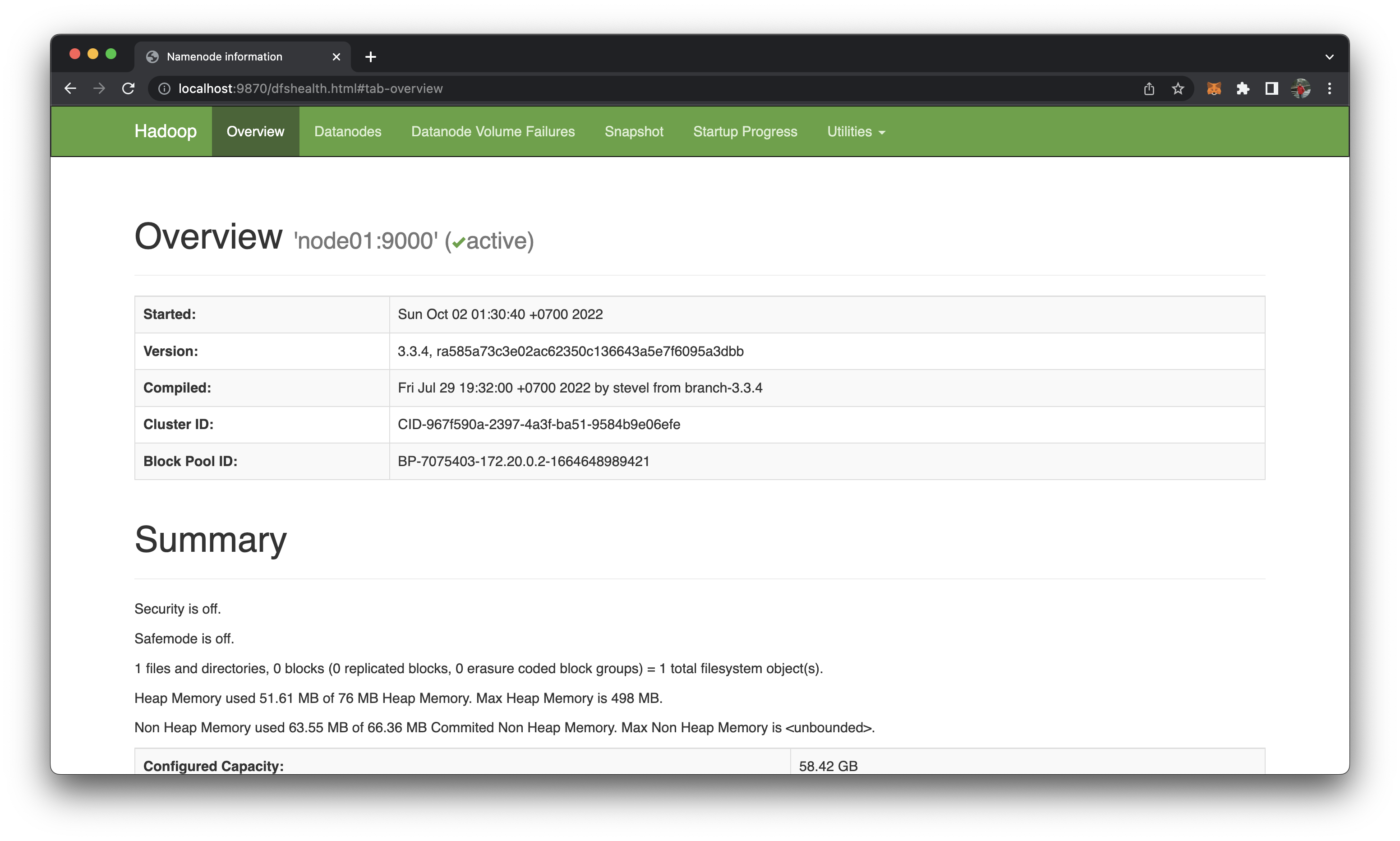
-
http://localhost:8088/hoặchttp://172.20.0.2:8088/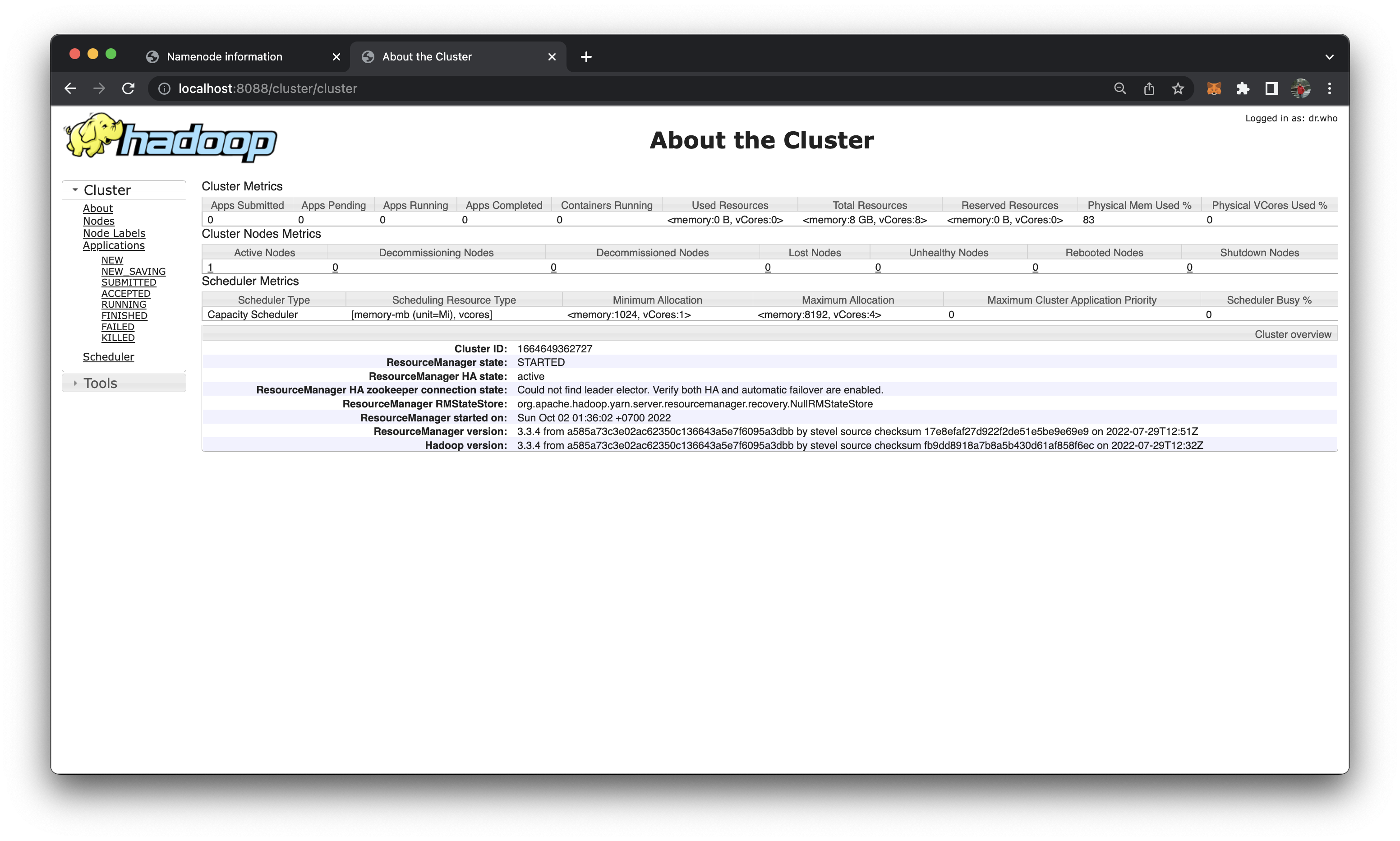
Thêm node mới vào cụm
Để thêm một node mới vào cụm thì trên node đó cũng thực hiện đầy đủ các bước ở trên. Do sử dụng Docker nên mình sẽ tạo một image từ container đang có
$ docker commit node01 hadoop
Run container mới từ image vừa tạo
$ docker run -it --name node02 --hostname node02 --network hadoop hadoop
Trên node02 ta start service ssh và xoá thư mục data cũ đi
$ service ssh start
$ rm -rf /home/hdfs/hadoop
$ rm -rf /home/yarn/hadoop
Cập nhật ip, hostname của Namenode cho node02
- File
/etc/hosts
172.20.0.3 node02
172.20.0.2 node01
Trên node01 chúng ta bổ sung thêm ip và hostname của node02
- File
/etc/hosts
172.20.0.2 node01
172.20.0.3 node02
- File
$HADOOP_HOME/etc/hadoop/workers
node01
node02
Sau đó start all các dịch vụ của hadoop trên node01
$ $HADOOP_HOME/sbin/start-all.sh
Kiểm tra node02 đã được add vào chưa
-
http://localhost:9870/dfshealth.html#tab-datanode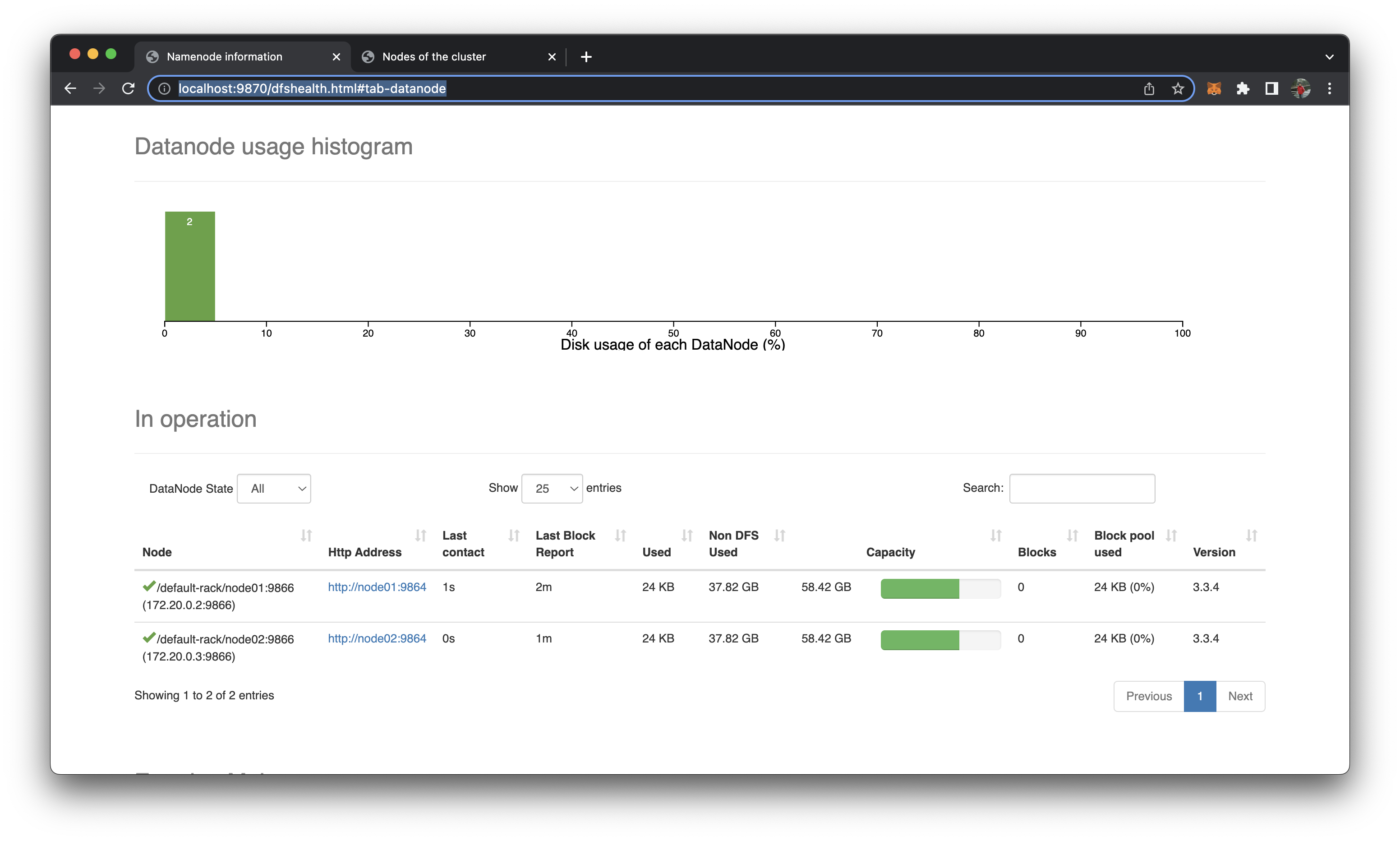
-
http://localhost:8088/cluster/nodes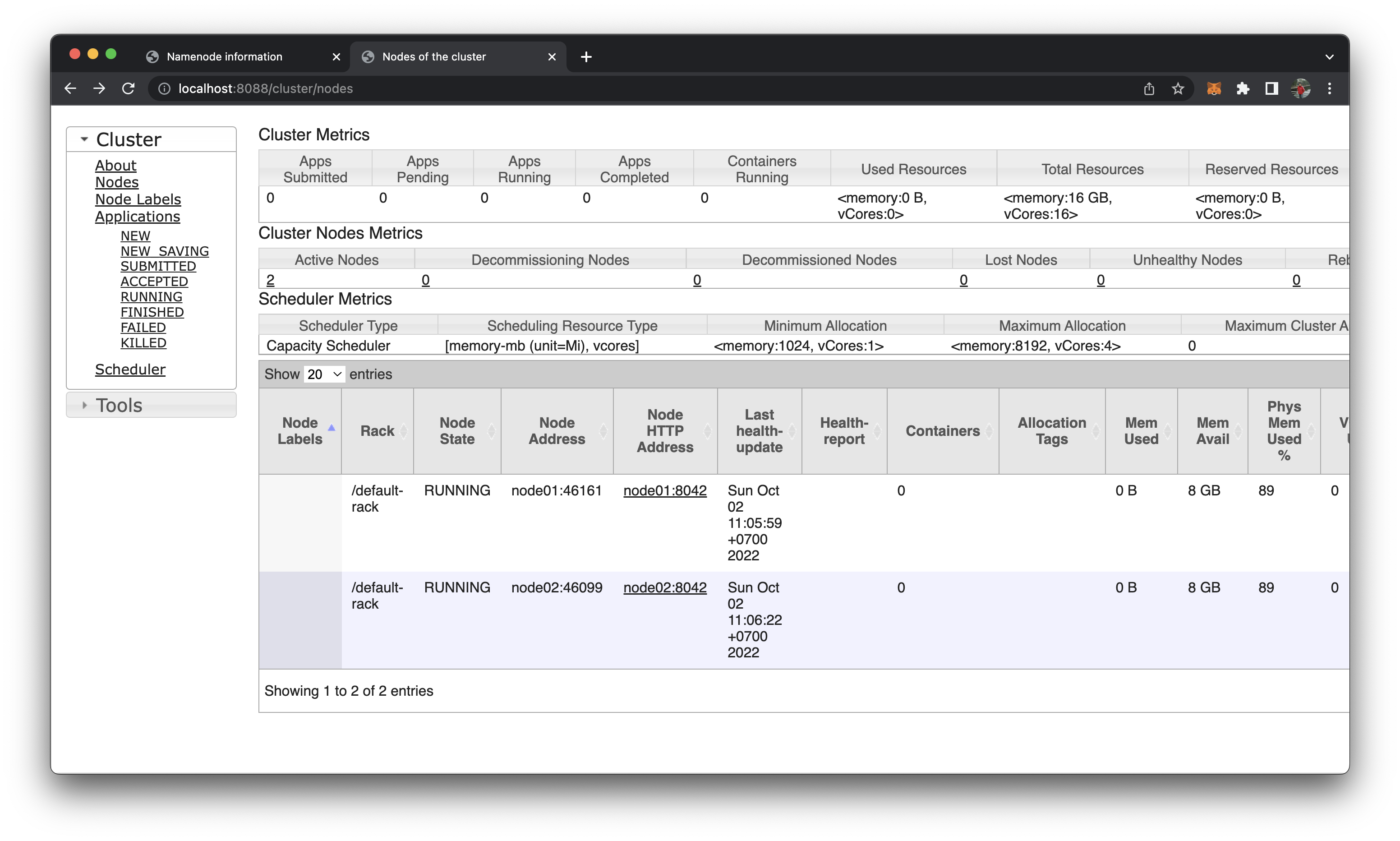
Làm tương tự với node03 ta sẽ được cụm 3 node
Lưu ý do mình clone node02, node03 từ node01 ban đầu nên không cần add ssh-key của các tài khoản (do đã sử dụng chung một ssh-key). Nếu cài trên hệ thống thật thì cần copy public key từ mỗi account trên namenode và add vào authorized_keys của account tương ứng trên datanode.
Hướng dẫn sử dụng cơ bản
Để start tất cả các dịch vụ trong cụm Hadoop ta cần vào master node (trong bài này là node01) sử dụng account root
$ $HADOOP_HOME/sbin/start-all.sh
Master node cần có ip và hostname của tất cả các slave node trong file
/etc/hostsvà mỗi accounthdfs,yarn,mapredcủa master node đều có thể ssh đến account tương ứng trên các slave node. Mỗi Slave node đều phải connect được đến Master node thông qua hostname.
Để tắt tất cả dịch vụ của cụm Hadoop
$ $HADOOP_HOME/sbin/stop-all.sh
Kết luận
Như vậy trong bài viết này mình đã giới thiệu đầy đủ về quá trình cài Hadoop của mình, các bạn làm theo có vấn đề gì thì cố gắng tự giải quyết nha :). Hẹn gặp lại trong bài viết sau.
![]() Hiện tại mình đang phát triển một số kênh phân tích dữ liệu blockchain hàng ngày trên nền tảng chainslake.com:
Hiện tại mình đang phát triển một số kênh phân tích dữ liệu blockchain hàng ngày trên nền tảng chainslake.com:
- https://chainslake.com/@bitcoin
- https://chainslake.com/@ethereum
- https://chainslake.com/@binance
- https://chainslake.com/@aave
- https://chainslake.com/@nftfi
- https://chainslake.com/@opensea
- https://chainslake.com/@uniswap
Chainslake là nền tảng phân tích dữ liệu blockchain hoàn toàn miễn phí, do mình phát triển dựa trên những kiến thức được trình bày trong chính blog này. Rất mong sự ủng hộ từ các bạn.