Hướng dẫn Spark cơ bản cho người mới bắt đầu
- 10 minsTrong bài viết trước, mình đã giới thiệu với các bạn về mô hình tính toán MapReduce cho phép có thể xử lý lượng dữ liệu lớn được lưu trữ trên nhiều máy tính. Tuy nhiên mô hình MapReduce có một nhược điểm là nó liên tục phải đọc ghi dữ liệu từ ổ đĩa cứng, điều này làm cho chương trình MapReduce trở nên chậm chạp. Để giải quyết vấn đề này, Spark đã ra đời dựa trên ý tưởng rằng: dữ liệu chỉ cần đọc 1 lần từ input và ghi 1 lần ra output, trong suốt quá trình xử lý dữ liệu trung gian sẽ được nằm trên bộ nhớ thay vì phải liên tục đọc ghi từ ổ đĩa cứng từ đó giúp cải thiện đáng kể hiệu năng so với MapReduce. Thực nghiệm cho thấy Spark có thể xử lý nhanh hơn tới 100 lần so với MapReduce.
Trước khi vào nội dung của bài viết mình xin phép mọi người 1 phút. Hiện tại mình đang phát triển nền tảng phân tích dữ liệu và chia sẻ Insight Blockchain có tên là chainslake. Mục tiêu của mình là xây dựng cộng đồng chuyên gia phân tích dữ liệu Blockchain tại Việt Nam, cùng nhau khai thác Data warehouse blockchain để giải quyết các bài toán về phân tích, tìm kiếm Insight, truy vết giao dịch… Đây là link tài liệu của dự án, rất mong nhận được sự ủng hộ từ các bạn.
Nội dung
- Giới thiệu tổng quan
- Cài đặt môi trường phát triển
- Ví dụ bắt đầu với Spark
- Chạy chương trình Spark trên Hadoop cluster
- Kết luận
Giới thiệu tổng quan
Spark là engine tính toán đa dụng, nhanh và phân tán, có khả năng xử lý được lượng dữ liệu khổng lồ song song và phân tán trên nhiều máy tính đồng thời. Dưới đây là sơ đồ mô tả hoạt động của một ứng dụng Spark khi chạy trên một cụm máy tính:
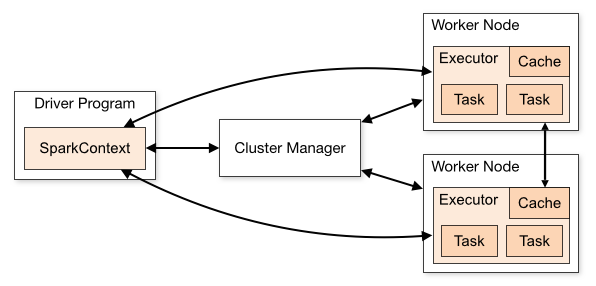
- Driver Program: Trình điều khiển là tiến trình chính (main) chạy trên Master node có nhiệm vụ điều khiển, lập lịch, điều phối công việc trong toàn bộ chương trình. Là tiến trình được khởi tạo đầu tiên và kết thúc cuối cùng.
- Spark context: Là một đối tượng được khởi tạo bởi Driver program nằm trên master node, lưu trữ toàn bộ các thông tin về cấu trúc dữ liệu, cầu hình, kết nối đến Cluster manager.
- Cluster Manager: Quản lý và điều phối tài nguyên trong cụm, Spark context có thể làm việc với nhiều loại Cluster manager khác nhau như Standalone, Apache Mesos, Hadoop YARN, Kubernetes.
- Executor: Là các tiến trình chạy trên các Worker node, tiếp nhận và xử lý các task từ Driver.
Cũng giống như MapReduce, chương trình Spark sẽ được đưa đến các node đang có dữ liệu, một node sẽ được chọn làm master để chạy tiến trình driver, các node khác sẽ làm worker. Driver tạo task và phân chia cho các worker theo nguyên tắc xử lý địa phương, tức là dữ liệu trên node nào sẽ được xử lý bởi executor trên node đó. Để tăng hiệu quả xử lý, dữ liệu sẽ được tải lên và duy trì trong bộ nhớ của các worker trong một cấu trúc dữ liệu gọi là Resilient Distributed Dataset (RDD) với các đặc điểm sau:
- Distributed: RDD có dạng
Collectioncủa cácElement, được chia nhỏ thành cácPartitionvà phân tán trên các node của cụm, từ cho phép dữ liệu trong RDD có thể được xử lý song song. - Read only: RDD chỉ có thể được tạo ra từ dữ liệu Input hoặc từ một RDD khác và không thể thay đổi sau khi tạo.
- Persist: Spark duy trì RDD trên bộ nhớ trong suốt quá trình chạy, cho phép chúng có thể được tái sử dụng nhiều lần.
- Fault tolerance: Cuối cùng RDD cũng có khả năng tự sửa chữa khi có node bị lỗi nhờ cơ chế tái tạo lại từ dữ liệu Input hoặc từ các RDD khác.
RDD cung cấp 2 kiểu Operaction là transformations và actions:
- Transformations: Là các nhóm các Operation tạo ra một RDD mới từ RDD đang có, ví dụ: map, flatMap, filter, mapPartition, reduceByKey, groupByKey…
- Actions: là nhóm các Operation cần trả về dữ liệu cho Driver sau khi thực hiện tính toán trên RDD, ví dụ: reduce, collect, count và các hàm save…
Tất cả các Transformations đều là lazy, chúng sẽ không thực hiện việc xử lý dữ liệu khi được gọi đến, chỉ đến khi một Actions được gọi và cần đến kết quả của một Transformation thì lúc đó Transformation mới thực hiện việc tính toán. Thiết kế này giúp cho Spark chạy hiệu quả hơn do không phải lưu trữ quá nhiều dữ liệu trung gian chưa dùng đến trên bộ nhớ. Sau mỗi lần gọi Actions thì các dữ liệu trung gian cũng được giải phóng khỏi bộ nhớ, nếu người dùng muốn giữ lại nó để sử dụng trong các Actions tiếp theo họ có thể sử dụng phương thức persist hoặc cache.
Cùng với RDD, Spark cũng cung cấp Dataframe và Dataset đều là các cấu trúc dữ liệu phân tán. Trong Dataframe dữ liệu được tổ chức thành các tên cột giống với bảng trong cơ sở dữ liệu, còn trong Dataset mỗi element là một JVM type-safe Object do đó rất thuận tiện để xử lý dạng dữ liệu có cấu trúc.
Cài đặt môi trường phát triển
Cơ bản là như vậy, giờ chúng ta sẽ bắt tay vào cài đặt và code thử nhé!
- Đầu tiên các bạn tải về phiên bản mới nhất của Spark tại đây
- Tiếp theo bạn giải nén và copy vào thư mục cài đặt trên máy tính của bạn (trên máy tính của mình là thư mục
~/Install)$ tar -xzvf spark-3.1.2-bin-hadoop3.2.tgz $ mv spark-3.1.2-bin-hadoop3.2 ~/Install/spark - Bổ sung biến môi trường
export SPARK_HOME=~/Install/spark export PATH=$PATH:$SPARK_HOME/bin - Load lại biến môi trường
$ source ~/.bash_profile -
Bạn cũng cần cài đặt Java và Scala. Lưu ý cần chọn phiên bản Java và Scala phù hợp với Spark, ở đây mình chọn Java 11 và Scala 2.12
- Kiểm tra Spark đã cài thành công hay chưa bằng
spark-shell
$ spark-shell
Spark context Web UI available at http://localhost:4041
Spark context available as 'sc' (master = local[*], app id = local-1676799060327).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 11.0.17)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Ví dụ bắt đầu với Spark
Với Spark thì mình sử dụng ngôn ngữ Scala cùng với IDE là Intellij. Để tiện sử dụng, mình đã tạo sẵn một project Spark mẫu tại đây các bạn có thể clone về hoặc fork lại nhé. Trong project này có một số lưu ý sau:
- Cách build và run mình đã viết trong file
Readme.md. - Để tạo một Job mới bạn cần tạo một
objectscala trong packagejobvà extendsJobInf, đặt code xử lý logic trong phương thứcrun, khai báo tên job trongJobFactory(xem ví dụ của jobDemo). - Để run một job mới trên dev bạn cần tạo một thư mục với tên job trong thư mục
run/dev, trong thư mục có 2 file làapplication.propertiesvàrun.sh.application.propertiessẽ chứa các tham số cấu hình cho job và yêu cầu bắt buộc cóapp_nameđểJobFactorycó thể khởi tạo đúng Job.run.shchứa lệnh thực thispark-submit:spark-submit --class Main \ --master local[*] \ # cấu hình cluster manager --deploy-mode client \ # Cấu hình deploy: client (driver nằm trên node hiện tại) or cluster (driver nằm trên một node bất kỳ của cụm) --driver-memory 2g \ # Cấu hình ram cho driver --executor-memory 2g \ # Cấu hình ram cho executor --executor-cores 2 \ # Cấu hình số nhân (luồng) cho executor --num-executors 1 \ # Cấu hình số lượng excutor --conf spark.dynamicAllocation.enabled=false \ --conf spark.scheduler.mode=FAIR \ --packages org.web3j:abi:4.5.10,org.postgresql:postgresql:42.5.0 \ # Cấu hình các thư viện bổ sung --files ./application.properties \ ../spark_template_dev.jar \ application.properties & - Để cài thêm thư viện phục vụ cho việc Dev bạn cần bổ sung thêm thư viện vào biến
libraryDependenciestrong filebuild.sbt, bạn có thể tìm thư viện và version của nó tại đây.
Chạy chương trình Spark trên Hadoop cluster
Trước hết bạn cần cài đặt Spark lên cụm Hadoop theo hướng dẫn tại đây. Lưu ý rằng do Spark sẽ sử dụng Yarn làm Cluster Manager nên bạn chỉ cần cài Spark trên 1 node và sẽ thực thi các job spark trên chính node đó.
Tiếp theo bạn kéo code từ git về node đã cài Spark và chạy job trong thư mục run/product, lưu ý cần sửa cấu hình --master trong file run.sh từ local[*] sang yarn.
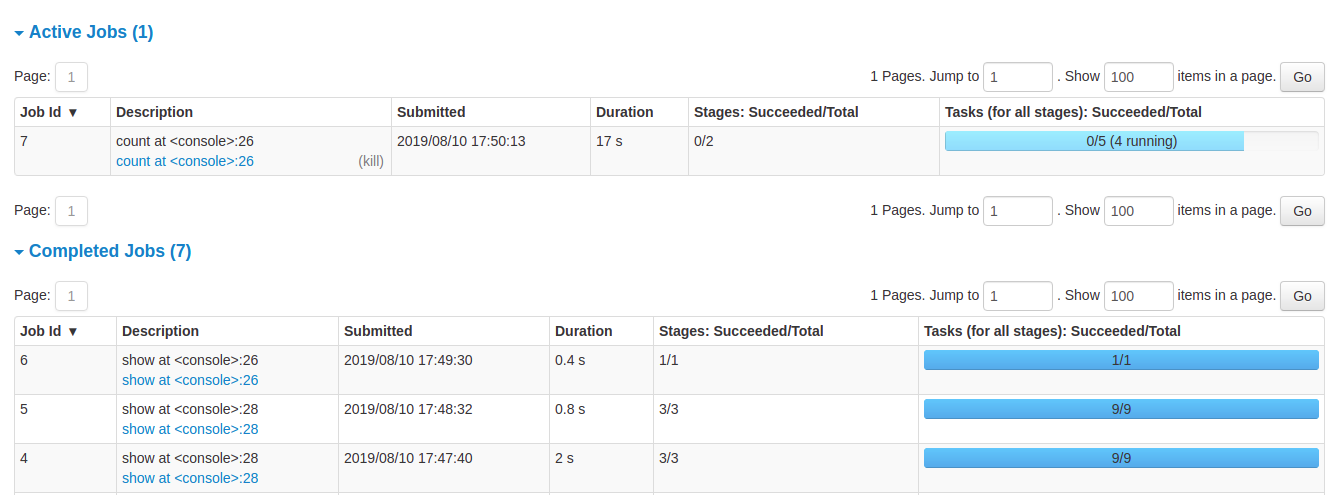
Khi một ứng dụng Spark đang chạy ta có thể theo dõi nó trên giao diện Spark UI
Kết luận
Bài viết hôm nay mình sẽ dừng lại ở việc giới thiệu những khái niệm và kiến thức cơ bản nhất về Spark cùng với đó là những hướng dẫn ban đầu để cài đặt và làm quen với framework này. Các bài viết tiếp theo mình sẽ đi sâu hơn vào các nội dung liên quan đến lập trình Spark, sử dụng các module như Spark Sql, Spark Streaming… Hẹn gặp lại các bạn trong các bài viết tới nhé!