DWH 1: Hướng dẫn cài đặt Data Warehouse trên Hadoop
- 17 minsTrong hoạt động kinh doanh của mình, người chủ doanh nghiệp luôn cần phải đưa ra quyết định, các quyết định đúng đắn sẽ giúp doanh nghiệp ổn định và phát triển, ngược lại quyết định sai lầm sẽ dẫn đến thua lỗ thậm chí phá sản. Business Intelligence (BI) là một hệ thống tổng hợp thông tin, đưa ra báo cáo phân tích thông minh, xây dựng các mô hình dự báo từ dữ liệu cho phép chủ doanh nghiệp có góc nhìn toàn diện về doanh nghiệp mình từ đó đưa ra những quyết định có lợi cho hoạt động dinh doanh. Trong bài viết này mình sẽ giới thiệu với các bạn về Data warehouse (DWH) được ví như “chiếc dạ dày”, là kho chứa toàn bộ dữ liệu của hệ thống BI, do dung lượng của bài viết nên mình sẽ tách thành 2 phần: Phần 1 là hướng dẫn cài đặt, phần 2 là ứng dụng DWH cho một bài toán cụ thể.
Nội dung
- Giới thiệu tổng quan
- Kiến trúc thiết kế
- Cài đặt Spark
- Cài đặt Postgresql
- Cấu hình Spark Thrift Server (Hive)
- Cài đặt DBT
- Cài đặt Superset
- Cài đặt Airflow
- Kết luận
Giới thiệu tổng quan
Theo định nghĩa từ Oracle, Data Warehouse là một loại hệ thống quản trị dữ liệu được thiết kế để hỗ trợ cho các hoạt động phân tích và trí tuệ doanh nghiệp (Business Intelligence). Dữ liệu trong data warehouse là dữ liệu có cấu trúc giống như database tuy nhiên có một số khác biệt giữa 2 hệ thống này như sau:
- Database dùng cho mục đích thu thập dữ liệu, sử dụng cho các hoạt động hàng ngày, còn DWH dùng cho phân tích dữ liệu.
- Dữ liệu trong Database được thêm, sửa, xoá trực tiếp bởi các ứng dụng còn dữ liệu trong DWH được import vào từ nhiều nguồn khác nhau.
- Bảng trong Database được thiết kế theo dạng chuẩn để tránh dư thừa và đảm bảo chính xác khi thêm sửa, xoá, còn trong DWH dữ liệu có thể lặp lại để truy vấn nhanh hơn nhưng hạn chế khi chỉnh sửa dữ liệu.
- Database tối ưu cho các loại truy vấn thêm, sửa, xoá, tuân thủ ACID để đảm bảo tính toàn vẹn cho dữ liệu, còn DWH tối ưu cho các truy vấn phân tích, tổng hợp phức tạp, chuyên sâu và không phải lúc nào cũng tuân thủ ACID.
Kiến trúc thiết kế
Có nhiều cách để thiết kế một Data Warehouse, nó sẽ phụ thuộc vào nhu cầu sử dụng của mỗi người, ở đây mình dựa trên những mô tả kỹ thuật của Dune Analyst một startup cung cấp hạ tầng phân tích dữ liệu Blockchain, được định giá tới 1 tỷ đô vào thời điểm tháng 2/2022.
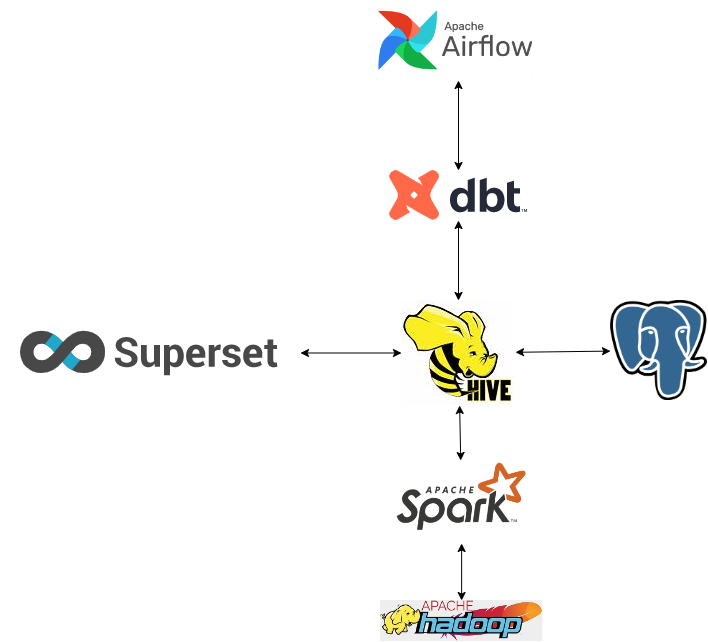
- DBT là một framework cho phép nhà phát triển có thể xây dựng các mô hình dữ liệu, các phép biến đổi dữ liệu một cách nhanh chóng bằng ngôn ngữ SQL quen thuộc.
- HDFS đóng vai trò là hạ tầng lưu trữ dữ liệu cho toàn bộ hệ thống, cung cấp khả năng mở rộng, tính sẵn sàng và chịu lỗi cao.
- Spark là một framework tính toán cho phép các ứng dụng có thể chạy song song phân tán trên nhiều máy tính để tăng hiệu quả trong xử lý dữ liệu lớn. Spark nhanh hơn Mapreduce tới hàng trăm lần nhờ khả năng sử dụng bộ nhớ RAM để lưu trữ các dữ liệu trung gian thay vì đọc ghi chúng trên ổ đĩa cứng.
- Hive trong hệ thống này đóng vai trò là một lớp giao diện cho phép các ứng dụng khác có thể sử dụng Spark và HDFS bằng ngôn ngữ SQL.
- Postgresql là cơ sở dữ liệu lưu trữ các Metadata cho Hive.
- Superset là công cụ để trình diễn dữ liệu dưới dạng các bảng, biểu đồ trong các dashboard phân tích.
- Airflow cung cấp khả năng quản lý, lập lịch thực thi luồng công việc, từ động hóa quy trình, hỗ trợ nhà phát triển theo dõi, phát hiện lỗi, đặc biệt là trong những luồng xử lý phức tạp, phụ thuộc lẫn nhau.
Cài đặt Spark
Bạn lên trang chủ của Spark tại đây để lấy link download. Vào thời điểm viết bài này phiên bản spark mới nhất là 3.3.4, tuy nhiên khi thử nghiệm mình thấy phiên bản này không tương tích với DBT và Hive nên mình sử dụng phiên bản spark thấp hơn là 3.3.2.
Lưu ý: Do đã có sẵn cụm Hadoop rồi (bạn xem lại hướng dẫn tại đây) nên chúng ta chỉ cần cài Spark trên 1 node (mình cái trên
node01), khi chạy job Spark ta để cấu hình--master yarnthì job sẽ được chạy được trên tất cả các node.
$ wget https://archive.apache.org/dist/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
$ tar -xzvf spark-3.3.2-bin-hadoop3.tgz
$ mv spark-3.3.2-bin-hadoop3 /lib/spark
$ mkdir /lib/spark/logs
$ chgrp hadoop -R /lib/spark
$ chmod g+w -R /lib/spark
Cấu hình các biến môi trường trong file /etc/bash.bashrc:
export SPARK_HOME=/lib/spark
export PATH=$PATH:$SPARK_HOME/bin
Cập nhật biến môi trường
$ source /etc/bash.bashrc
Tạo file $SPARK_HOME/conf/spark-env.sh:
cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh
Thêm cấu hình classpath vào file $SPARK_HOME/conf/spark-env.sh vừa tạo:
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
Kiểm tra xem đã chạy được Spark ở yarn mode hay chưa:
spark-shell --master yarn --deploy-mode client
Kết quả:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.3.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.17)
scala>
Cài đặt Postgresql
Bạn có thể cài đặt trực tiếp Posgresql hoặc sử dụng Docker, ở đây mình sẽ cài trực tiếp trên node01 theo hướng dẫn trên trang chủ tại đây.
Bật service postgresql
$ service postgresql start
Theo mặc định ta chỉ có thể connect vào Postgresql trên máy localhost thông qua user postgres:
Chuyển qua user postgres
$ su postgres
Vào giao diện Sql command:
[postgres]$ psql
Set lại mật khẩu cho account postgres:
postgres=# ALTER USER postgres WITH PASSWORD 'password';
Để có thể connect từ các máy khác (remote) ta cần sửa lại cấu hình như sau:
- Chỉnh sửa cấu hình trong:
postgresql.conf
listen_addresses = '*'
- Bổ sung cấu hình sau vào cuối file:
pg_hba.conf
host all all 0.0.0.0/0 md5
Lưu ý: để biết vị trí của 2 file cấu hình ta cần dùng lệnh
show config_file;vàshow hba_file;trên Sql command.
Restart posgresql
$ service postgresql restart
Kiểm tra xem đã connect được vào postgresql thông qua ip chưa:
$ psql -h node01 -p 5432 -U postgres -W
Cấu hình Spark Thrift Server (Hive)
Trong bản cài đặt của Spark đã có tích hợp sẵn Thrift Server (Hive), cho phép các ứng dụng khác có thể làm việc với Spark thông qua ngôn ngữ SQL của Hive. Ta cần cấu hình để dữ liệu được lưu trữ trên HDFS và metatadata lưu trữ trên postgresql như sau:
$SPARK_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.db.type</name>
<value>postgres</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://node01:9000/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:postgresql://node01:5432/metastore</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.postgresql.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>fs.hdfs.impl.disable.cache</name>
<value>true</value>
</property>
</configuration>
$SPARK_HOME/sbin/start-hive.sh
./start-thriftserver.sh --master yarn --deploy-mode client \
--driver-memory 4g \
--executor-memory 6g \
--executor-cores 4 \
--num-executors 2 \
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \
--conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"
Thrift server sẽ chạy như một Spark Job trên Yarn vì thế bạn có thể tùy chỉnh tài nguyên phù hợp (dung lượng ram, số nhân, số excurtors…) khi chạy.
Download driver postgresql vào thư mục $SPARK_HOME/jars/:
$ cd $SPARK_HOME/jars/
$ wget https://jdbc.postgresql.org/download/postgresql-42.5.1.jar
Download thư viện của Delta vào thư mục $SPARK_HOME/jars/:
$ cd $SPARK_HOME/jars/
$ wget https://repo1.maven.org/maven2/io/delta/delta-core_2.12/2.3.0/delta-core_2.12-2.3.0.jar
$ wget https://repo1.maven.org/maven2/io/delta/delta-storage/2.3.0/delta-storage-2.3.0.jar
Tạo user hive và thư mục warehouse trên HDFS:
$ useradd -g hadoop -m -s /bin/bash hive
[hive]$ hdfs dfs -mkdir -p /user/hive/warehouse
Tạo tạo user hive và database metastore trên Postgresql:
postgres=# CREATE DATABASE metastore;
postgres=# CREATE USER hive with password 'password';
postgres=# GRANT ALL PRIVILEGES ON DATABASE metastore to hive;
Chạy Thrift Server
$ chmod +x $SPARK_HOME/sbin/start-hive.sh
$ $SPARK_HOME/sbin/start-hive.sh
Job đã chạy trên Yarn tại http://172.24.0.2:8088/cluster/scheduler
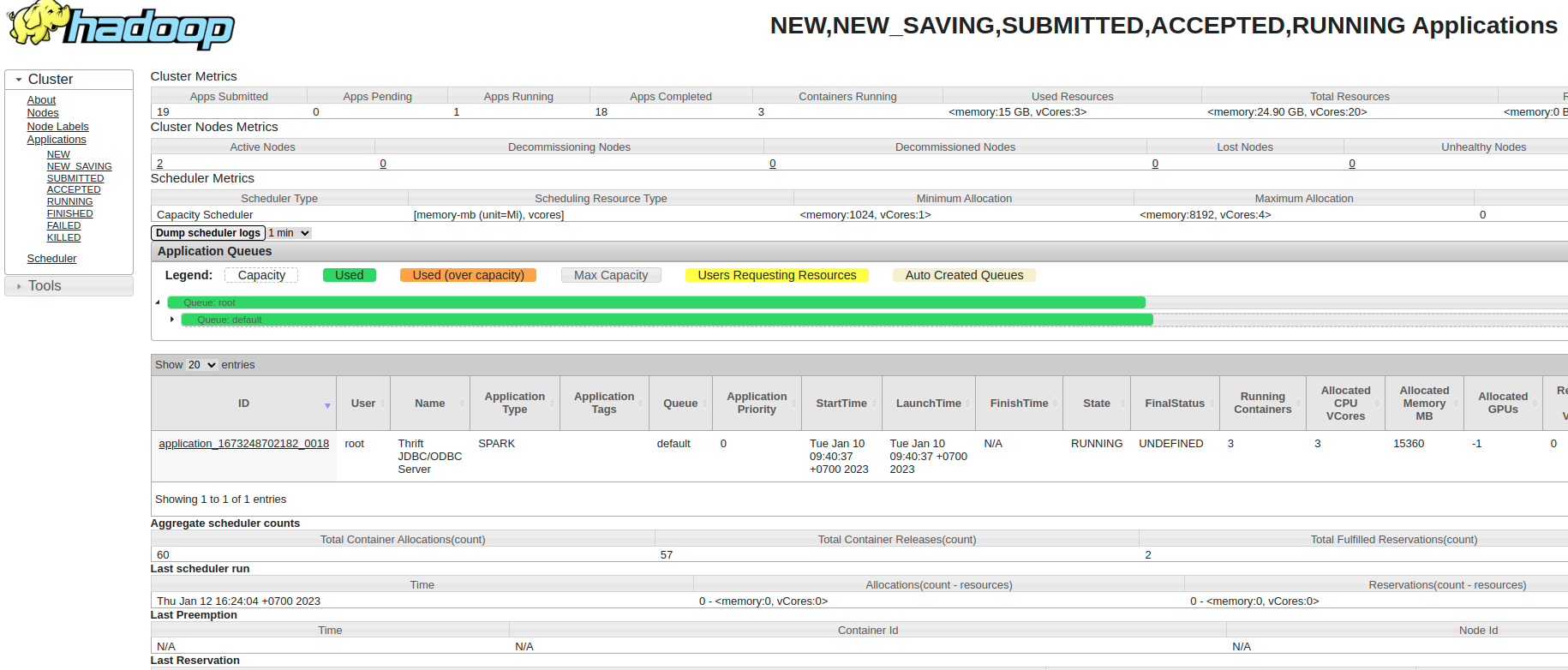
Tắt Thift Server:
$ $SPARK_HOME/sbin/stop-thriftserver.sh
Cài đặt DBT
Để cho nhanh thì mình sẽ sử dụng project example của DBT có sẵn trên Github tại đây. Mình sẽ giải thích kỹ hơn về project này trong bài viết sau.
Sử dụng git để clone project về máy:
$ git clone https://github.com/dbt-labs/jaffle_shop.git
Cài đặt môi trường phát triển và các thư viện qua Anaconda (bạn có thể tham khảo về Anaconda tại đây)
$ conda create -n dbt_example python=3.9
$ conda activate dbt_example
(dbt_example) $ pip install dbt-spark[PyHive]
Cấu hình connect đến Hive server trong file ~/.dbt/profiles.yml:
jaffle_shop:
outputs:
dev:
type: spark
method: thrift
host: node01
port: 10000
user: hive
dbname: jaffle_shop
schema: dbt_alice
threads: 4
prod:
type: spark
method: thrift
host: node01
port: 10000
user: hive
dbname: jaffle_shop
schema: dbt_alice
threads: 4
target: dev
Lần lượt chạy các lệnh sau để migrate các model thành các bảng trên DWH
$ dbt debug
$ dbt seed
$ dbt run
$ dbt test
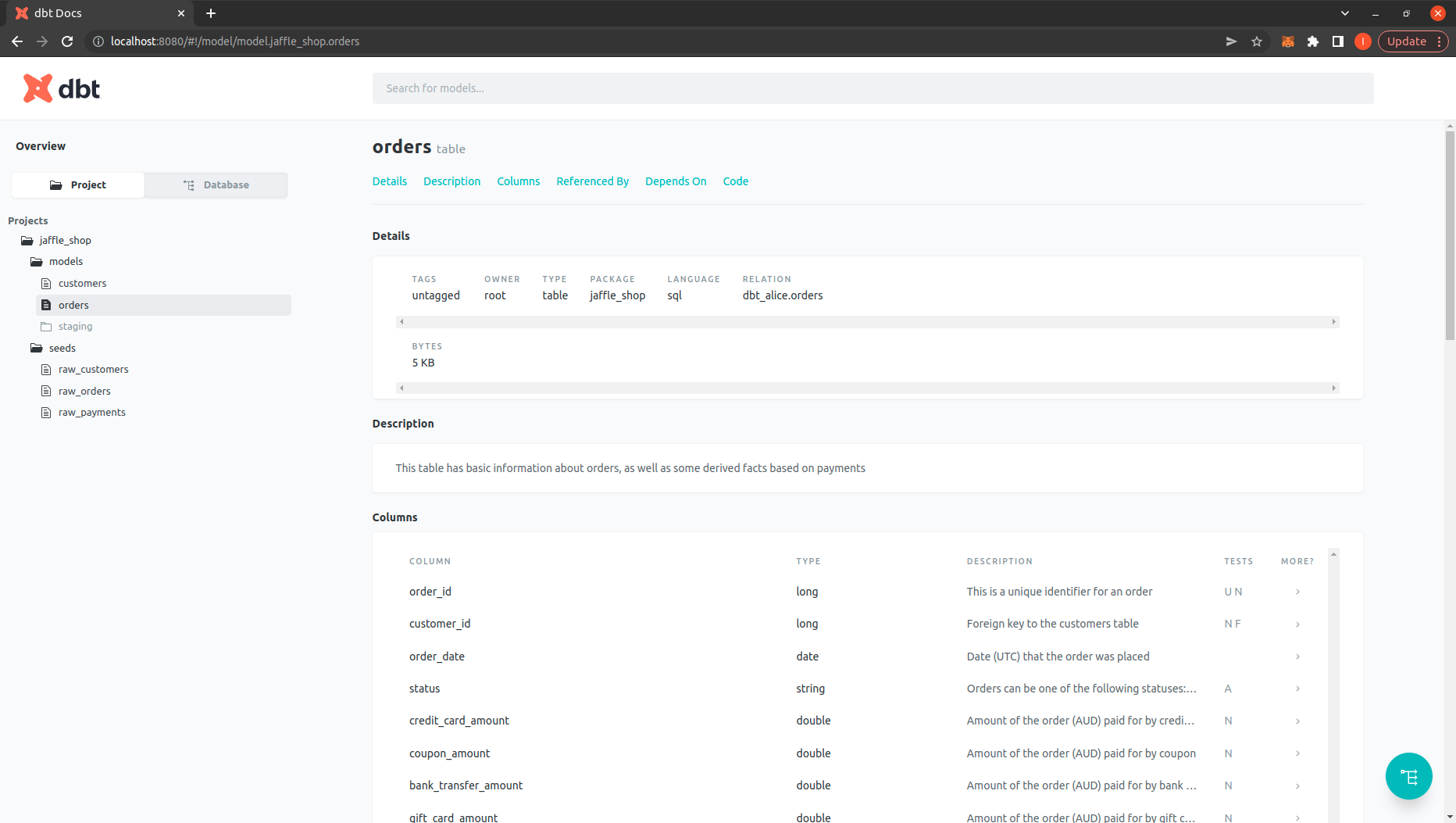
$ dbt docs generate
$ dbt docs serve
Kiểm tra project DBT đã chạy trên http://localhost:8080/
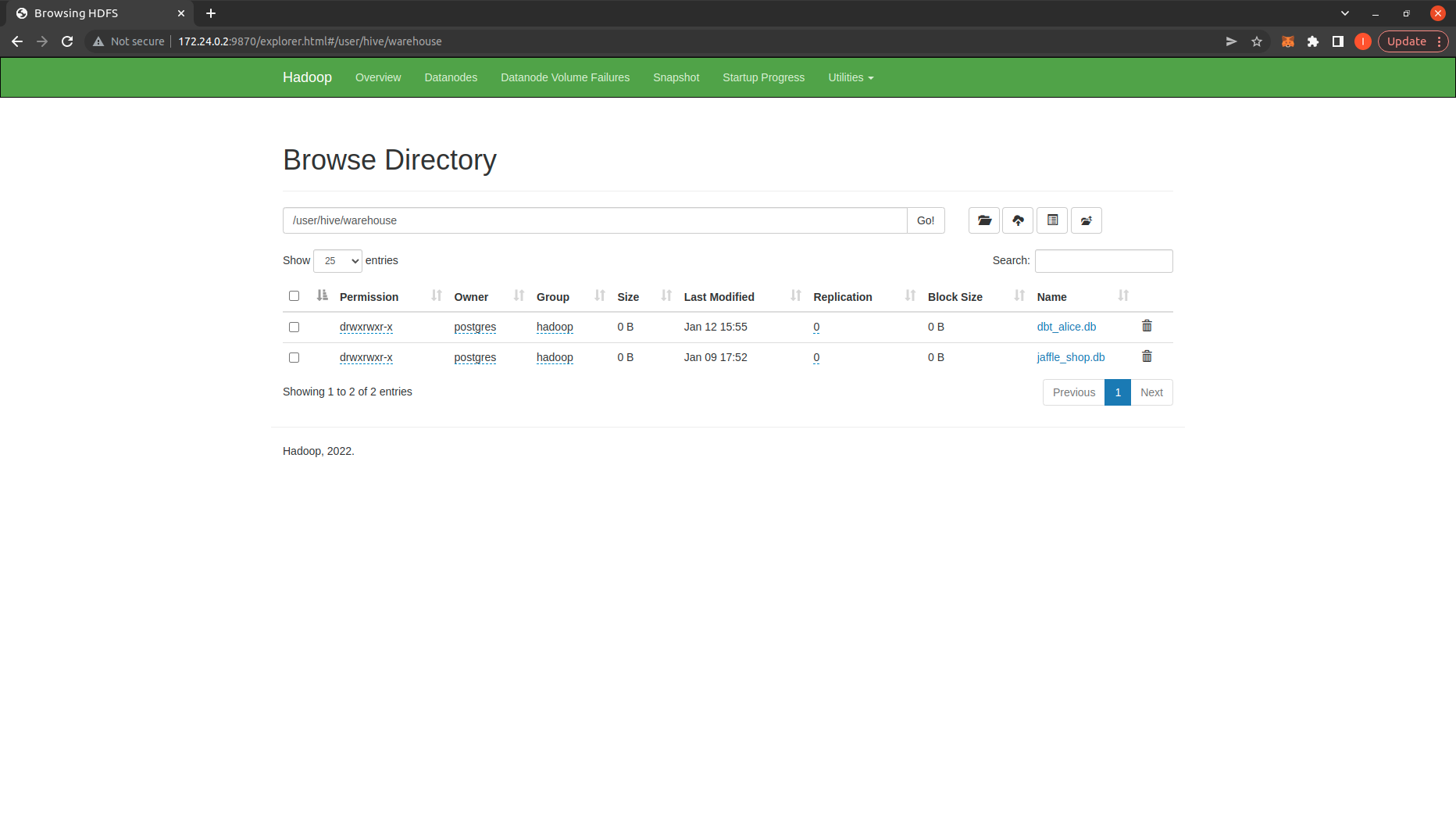
Kiểm tra thư mục warehouse trên HDFS: http://172.24.0.2:9870/explorer.html#/user/hive/warehouse ta có thể thấy có các database dữ liệu đã được tạo ra:
Cài đặt Superset
Chúng ta sẽ sử dụng Superset để xem dữ liệu được migrate trên trên DWH. Mình sẽ cài Superset thông qua docker
docker run -d --name superset --hostname superset --network hadoop apache/superset
docker exec -it superset superset fab create-admin \
--username admin \
--firstname Superset \
--lastname Admin \
--email admin@superset.com \
--password admin
Kiểm tra trên giao diện web của Superset: http://172.24.0.4:8088/
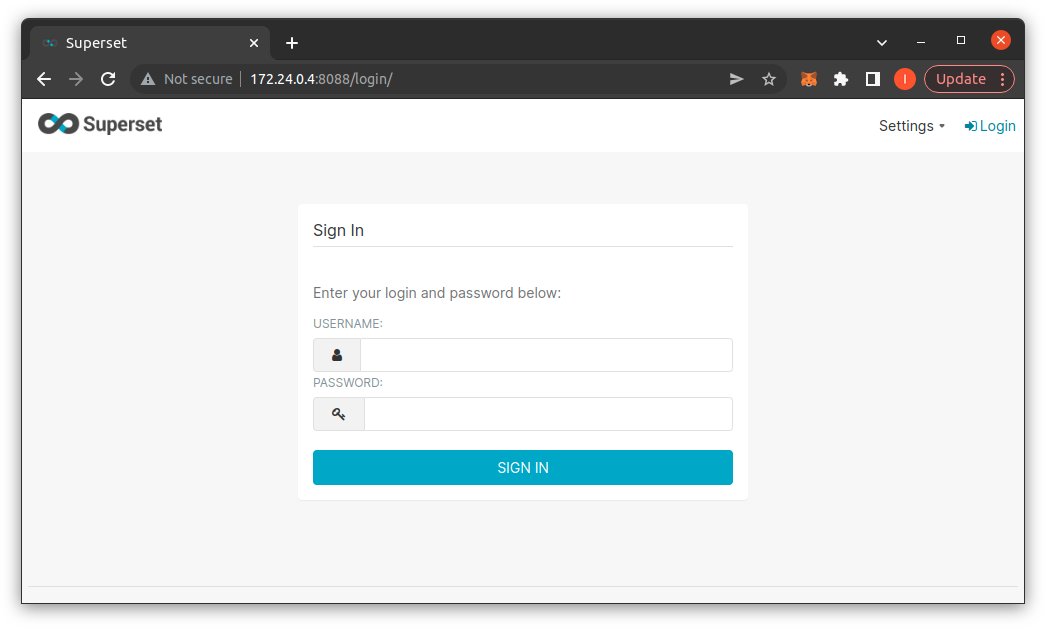
Đăng nhập bằng account admin/admin, sau đó vào Settting \ Databases Connections để tạo một Connection Database mới. Trong step 1 bạn chọn Supported Database là Apache Hive, trong phần SQLALCHEMY URI bạn điền url của Hive: hive://hive@172.24.0.2:10000/jaffle_shop sau đó chọn Connect.
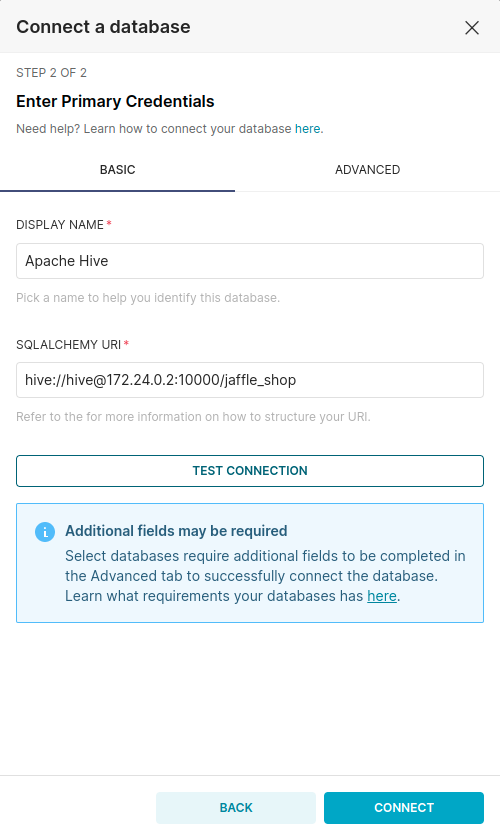
Để sử dụng các truy vấn vào DWH, bạn sử dụng giao diện SQL Lab trên Superset: 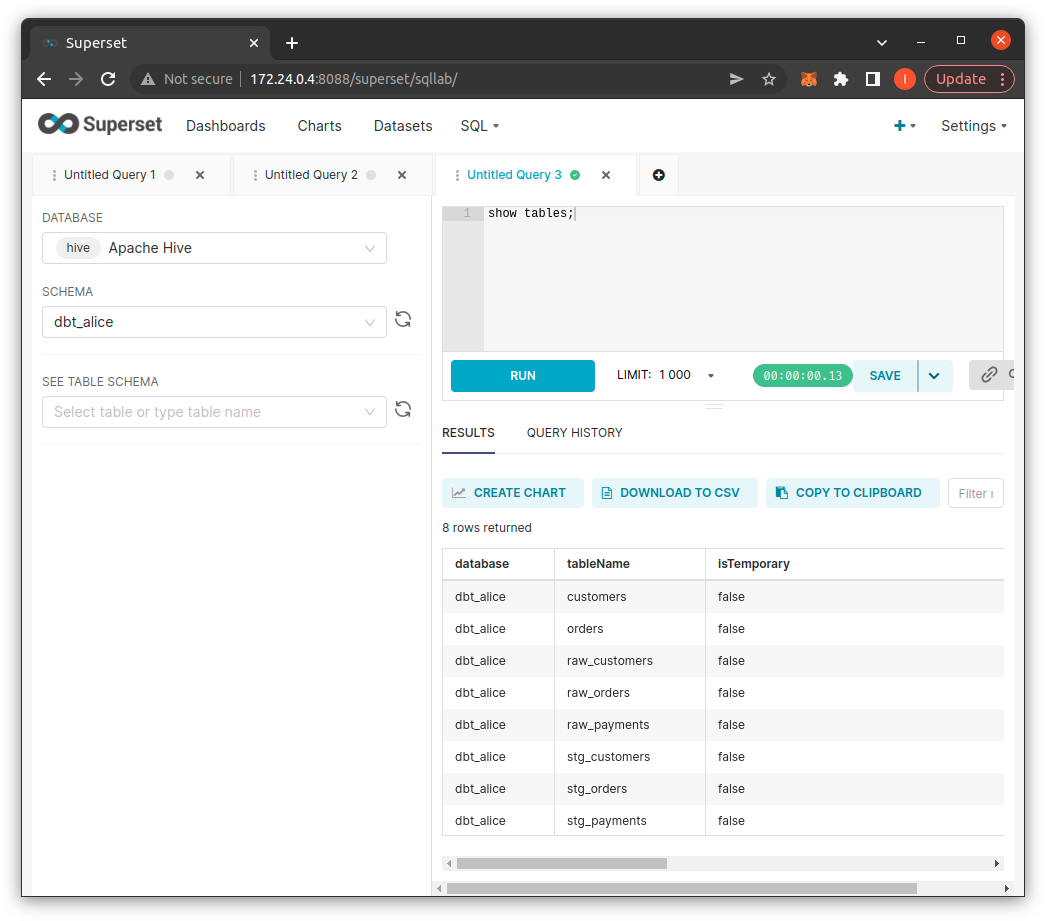
Cài đặt Airflow
Để đơn giản, bạn có thể cài trực tiếp Airflow trong project jaffle_shop của dbt, bạn xem hướng dẫn cài đặt tại đây
$ export AIRFLOW_HOME=~/airflow
$ export AIRFLOW_VERSION=2.5.0
$ export PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
$ export CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
$ pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
Tạo file DAG cho project jaffle_shop trong thư mục ~/airflow/dags/jaffle_shop/pipeline.py
from datetime import datetime, timedelta
import json
from airflow import DAG
from airflow.operators.bash import BashOperator
dag = DAG(
dag_id='dbt_dag',
start_date=datetime(2020, 12, 23),
description='A dbt wrapper for Airflow',
schedule_interval=timedelta(days=1),
)
def load_manifest():
local_filepath = "jaffle_shop/target/manifest.json"
with open(local_filepath) as f:
data = json.load(f)
return data
def make_dbt_task(node, dbt_verb):
"""Returns an Airflow operator either run and test an individual model"""
DBT_DIR = "jaffle_shop"
GLOBAL_CLI_FLAGS = "--no-write-json"
model = node.split(".")[-1]
if dbt_verb == "run":
dbt_task = BashOperator(
task_id=node,
bash_command=f"""
cd {DBT_DIR} &&
dbt {GLOBAL_CLI_FLAGS} {dbt_verb} --target prod --models {model}
""",
dag=dag,
)
elif dbt_verb == "test":
node_test = node.replace("model", "test")
dbt_task = BashOperator(
task_id=node_test,
bash_command=f"""
cd {DBT_DIR} &&
dbt {GLOBAL_CLI_FLAGS} {dbt_verb} --target prod --models {model}
""",
dag=dag,
)
return dbt_task
data = load_manifest()
dbt_tasks = {}
for node in data["nodes"].keys():
if node.split(".")[0] == "model":
node_test = node.replace("model", "test")
dbt_tasks[node] = make_dbt_task(node, "run")
dbt_tasks[node_test] = make_dbt_task(node, "test")
for node in data["nodes"].keys():
if node.split(".")[0] == "model":
# Set dependency to run tests on a model after model runs finishes
node_test = node.replace("model", "test")
dbt_tasks[node] >> dbt_tasks[node_test]
# Set all model -> model dependencies
for upstream_node in data["nodes"][node]["depends_on"]["nodes"]:
upstream_node_type = upstream_node.split(".")[0]
if upstream_node_type == "model":
dbt_tasks[upstream_node] >> dbt_tasks[node]
Lưu ý: update lại đường dẫn thư mục project jaffle_shop trong
local_filepathvàDBT_DIR
Chạy Airflow
$ airflow standalone
Bạn vào giao diện của airflow tại http://localhost:8080/ và login với account admin và mật khẩu được cung gấp trên command line.
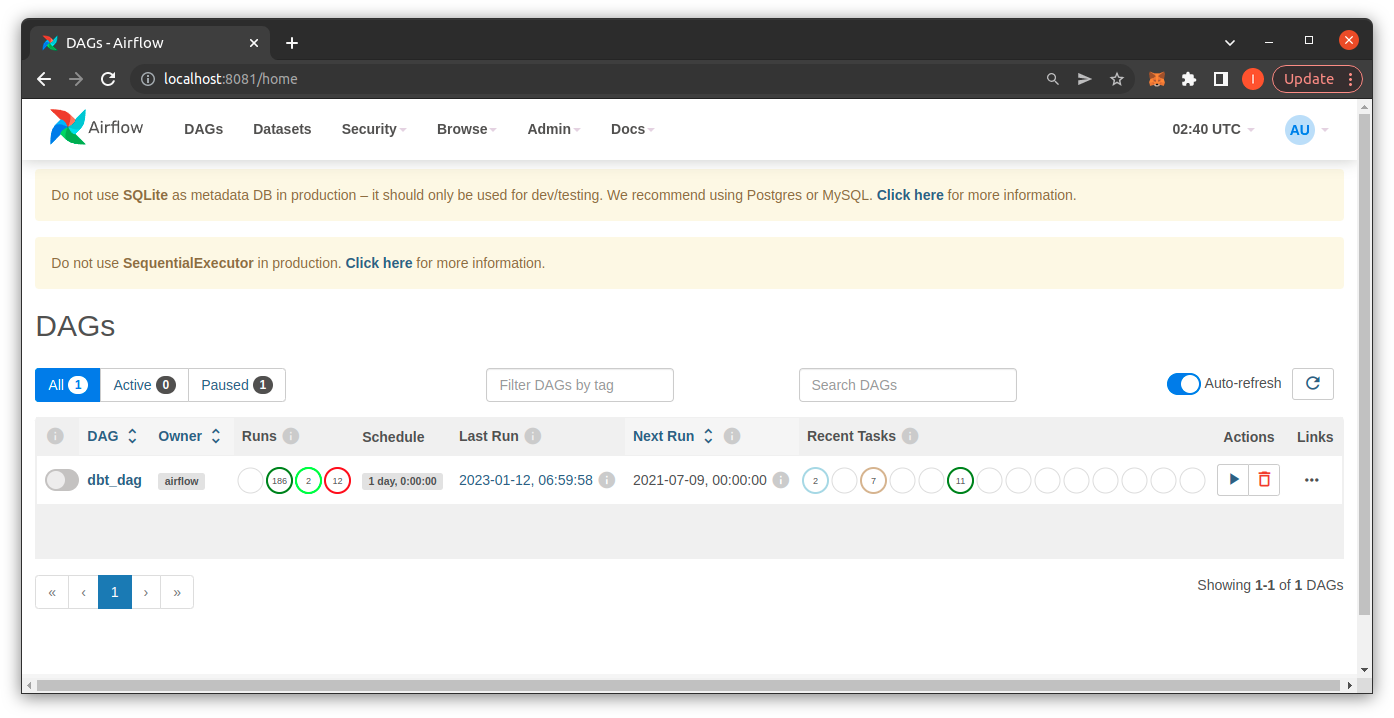
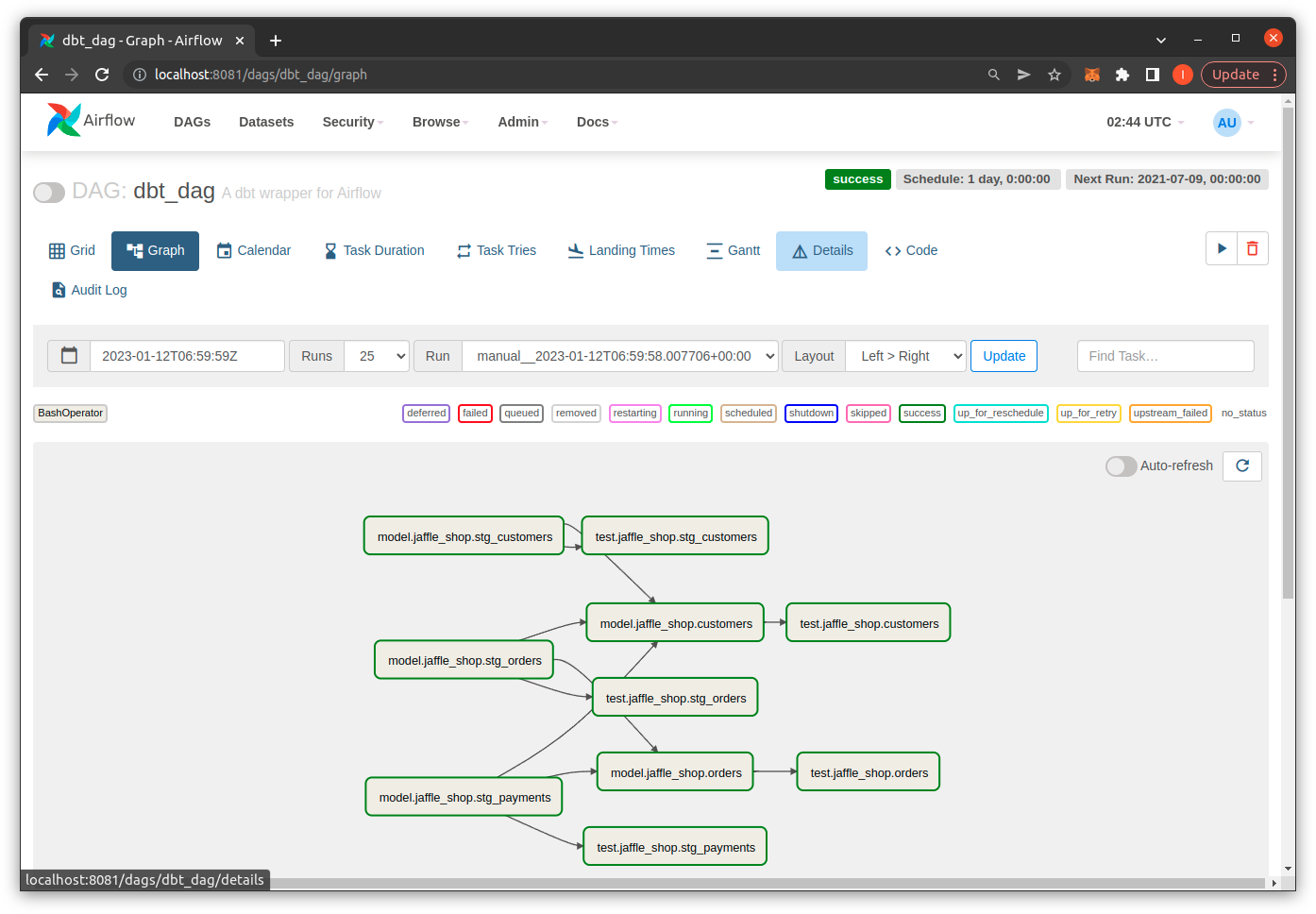
Kết luận
Trong bài viết này mình đã giới thiệu với mọi người kiến trúc và cách cài đặt một Data Warehouse trên Hadoop, đến đây cũng đã khá dài rồi nên phần ứng dụng của DWH mình sẽ trình bày trong bài viết sau nhé. Hẹn gặp lại.
![]() Hiện tại mình đang phát triển một số kênh phân tích dữ liệu blockchain hàng ngày trên nền tảng chainslake.com:
Hiện tại mình đang phát triển một số kênh phân tích dữ liệu blockchain hàng ngày trên nền tảng chainslake.com:
- https://chainslake.com/@bitcoin
- https://chainslake.com/@ethereum
- https://chainslake.com/@binance
- https://chainslake.com/@aave
- https://chainslake.com/@nftfi
- https://chainslake.com/@opensea
- https://chainslake.com/@uniswap
Chainslake là nền tảng phân tích dữ liệu blockchain hoàn toàn miễn phí, do mình phát triển dựa trên những kiến thức được trình bày trong chính blog này. Rất mong sự ủng hộ từ các bạn.